多条件查询优化
ES 在进行联合索引查询的时候,使用多个条件去进行筛选,那么多个筛选条件会获得多个倒排列表,如果这两个条件是一个"且"的操作,就需要将两个倒排列表进行合并取交集;如果这两个条件是一个"或"的操作,就需要将这两个倒排列表进行取"并集"。
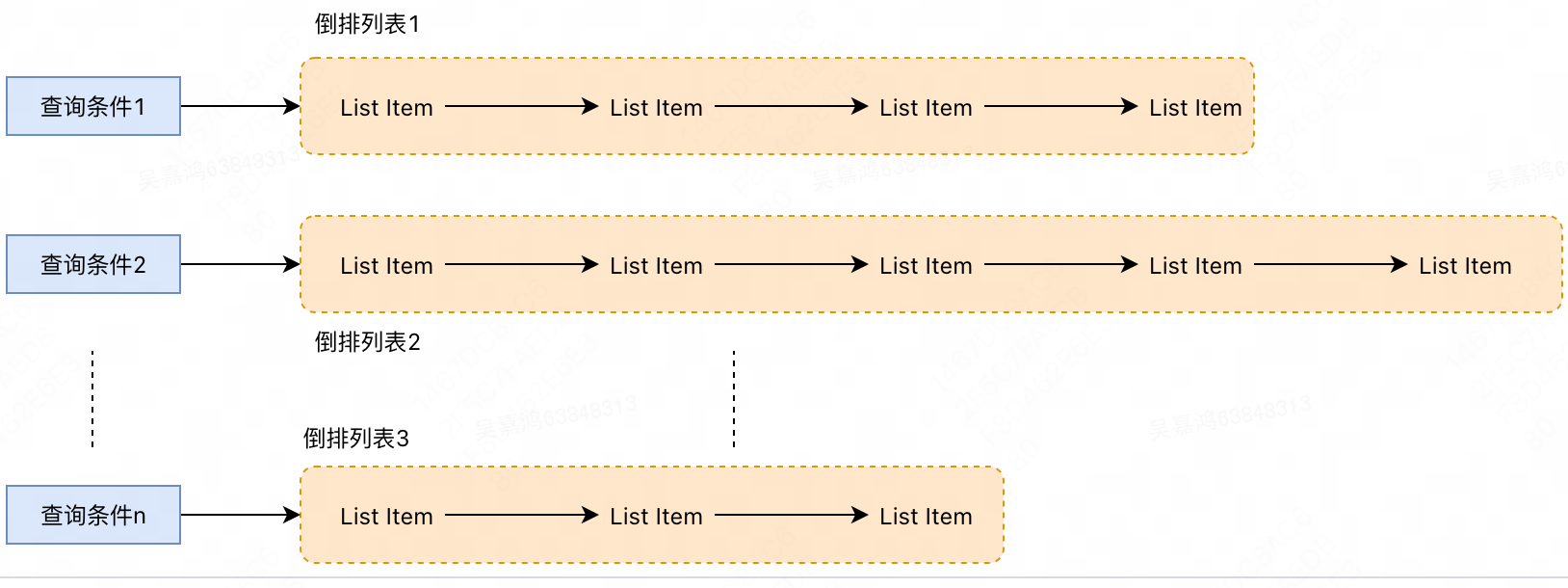
这个理论上的“与”合并的操作可不容易。对于 mysql 来说,如果你给两个字段都建立了索引,查询的时候只会选择其中最 selective 的来用,然后另外一个条件是在遍历行的过程中在内存中计算之后过滤掉。那么要如何才能联合使用两个索引呢?有两种办法:
- 跳表:同时遍历多个字段查询条件的倒排列表,互相 skip。
- bitset 结构:多多个字段筛选的的条件构建 bitset,然后多个 bitset 进行 AND 操作。
跳表合并查询
跳表的结构:
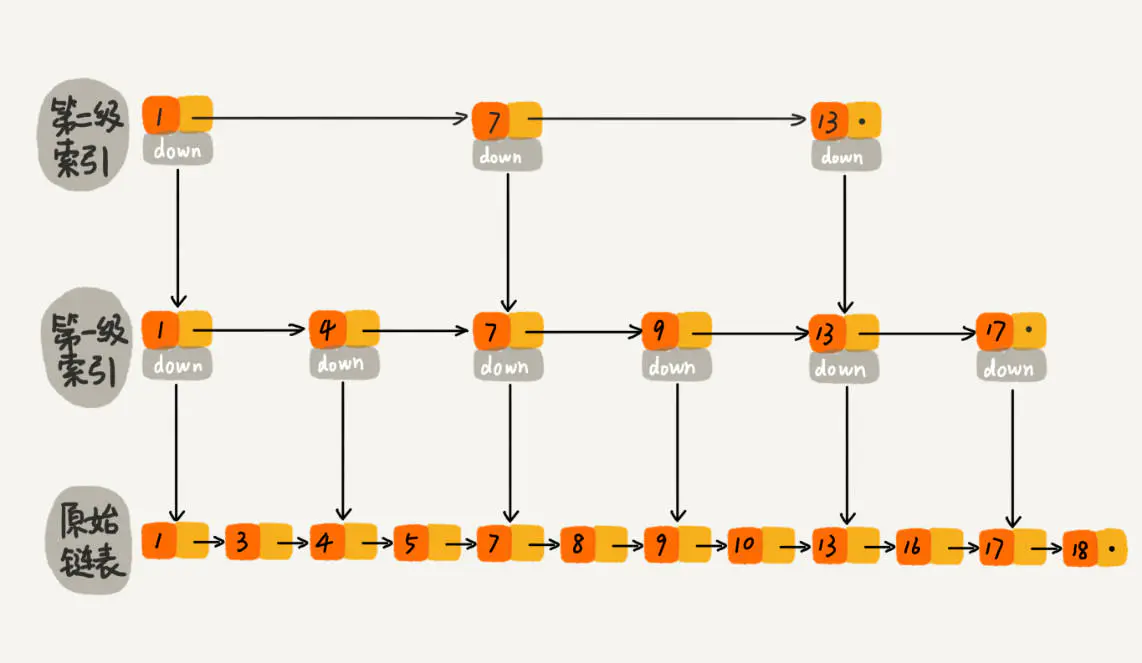
当元素数量较多时,索引提高的效率比较大,近似于二分查找。跳表是可以实现二分查找的有序链表。
ES 中对于跳跃表的使用,一般是在合并倒排列表的时候,也即联合索引查询的时候。
假设我们使用三个索引进行查询筛选,得到三个倒排列表,此处我们需要对三个倒排列表进行取"交集":
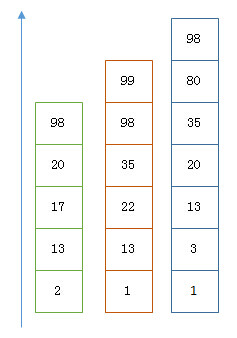
以上是三个 posting list。我们现在需要把它们用 AND 的关系合并,得出 posting list 的交集。首先选择最短的 posting list,然后从小到大遍历。遍历的过程可以跳过一些元素,比如我们遍历到绿色的 13 的时候,就可以跳过蓝色的 3 了,因为 3 比 13 要小。
Next -> 2
Advance(2) -> 13
Advance(13) -> 13
Already on 13
Advance(13) -> 13 MATCH!!!
Next -> 17
Advance(17) -> 22
Advance(22) -> 98
Advance(98) -> 98
Advance(98) -> 98 MATCH!!!
最后得出的交集是 [13,98],所需的时间比完整遍历三个 posting list 要快得多。但是前提是每个 list 需要指出 Advance 这个操作,快速移动指向的位置。
bitset 合并查询
Bitset 是一种很直观的数据结构,对应 posting list 如:[1,3,4,7,10]
对应的 bitset 就是:[1,0,1,1,0,0,1,0,0,1]

每个文档按照文档 id 排序对应其中的一个 bit。Bitset 自身就有压缩的特点,其用一个 byte 就可以代表 8 个文档。所以 100 万个文档只需要 12.5 万个 byte。但是考虑到文档可能有数十亿之多,在内存里保存 bitset 仍然是很奢侈的事情。而且对于个每一个 filter 都要消耗一个 bitset,比如 age=18 缓存起来的话是一个 bitset,18<=age<25 是另外一个 filter 缓存起来也要一个 bitset。
需要有一个数据结构能满足:
- 可以很压缩地保存上亿个 bit 代表对应的文档是否匹配 filter;
- 这个压缩的 bitset 仍然可以很快地进行 AND 和 OR 的逻辑操作。
Lucene 使用的这个数据结构叫做 Roaring Bitmap(RoaringBitmap 是高效压缩位图,简称 RBM):
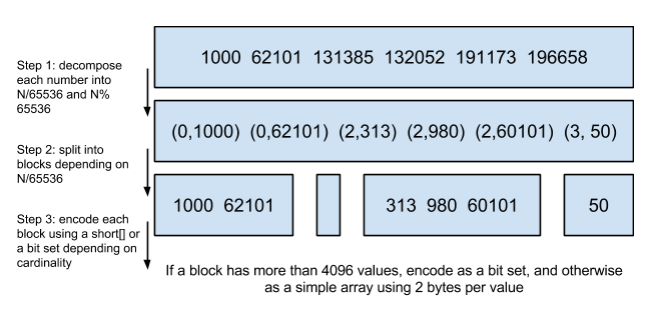
其压缩的思路其实很简单。与其保存 100 个 0,占用 100 个 bit。还不如保存 0 一次,然后声明这个 0 重复了 100 遍。上面这张图可以看出,如果没有某个桶下没有文档 id 匹配,这个桶是不会占用空间的。
Roaring Bitmap 的实现思路(假设在 32bit 系统上):
- 将 32bit int(无符号的)类型数据 划分为 2^16 个桶,即最多可能有 216=65536 个桶,内称为 container。用 container 来存放一个数值的低 16 位
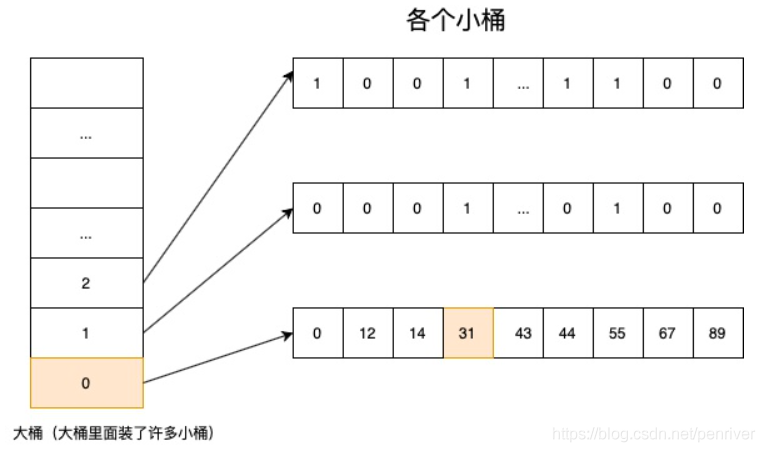
- 在存储和查询数值时,将数值 k 划分为高 16 位和低 16 位,取高 16 位值找到对应的桶,然后在将低 16 位值存放在相应的 Container 中(存储时如果找不到就会新建一个)
- 当桶下面的元素大于 65536 个时,会转换成 bitmapcontainer;小于 65536 是一个最大值为 4096 的 short 数组。

跳表和 bitset 的性能比较:
上面两种合并使用索引的方式都有其用途。Elasticsearch 对其性能有详细的对比(https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps )。简单的结论是:因为 Frame of Reference 编码是如此 高效,对于简单的相等条件的过滤缓存成纯内存的 bitset 还不如需要访问磁盘的 skip list 的方式要快。
排序和聚合的优化
我们知道倒排索引能够解决从词到文档的快速映射,但当我们需要对检索结果进行分类、排序、数学计算等聚合操作时需要文档号到值的快速映射,而原先不管是倒排索引还是行式存储的文档都无法满足要求。
假设我要根据 content 搜索,然后根据 time 字段排序,因为倒排索引是一个字段对应一个 docId 集合的,所以 query 阶段我只能取回 docId,没有更多字段的值,所以需要有一个地方获取 time 的值。倒排索引如下:
| term | docId |
|---|---|
| 10 | 2 |
| 13 | 3 |
| 14 | 1、5、8 |
| 16 | 7、9、10 |
这样的结构是没法直接获取到 time 字段的,所以只有遍历看看我这些 docId 的 time 值都对应是多少,所以这一步是要通过 docId 获取 fieldvalue的,遍历倒排索引效率会很低。因为一般来我们并不需要整个结果集,只需要按一定条件 topK。
原先 Lucene 4.0 版本之前,Lucene 实现这种需求是通过 FieldCache,它的原理是通过按列逆转倒排表将(field value ->doc)映射变成(doc -> field value)映射,也就是构建文档 id 到字段值的正排索引。

FieldCache 简单抽象的理解就是一个大数组,数组的下标表示 docId,数组中的值表示这个 field 的 value。上面的步骤当我需要按照 time 排序时,假设过滤出 100 个 docID,就可以拿他们去数组中直接取到 time 值然后排序,获取排序字段的时间复杂度瞬间变成 O(n) (n 为 doc 个数),效率好多了。
但这种实现方法有着两大显著问题:
- 构建时间长。
- 内存占用大,易 OutOfMemory,且影响垃圾回收。
因此 4.0 版本后 Lucene 推出了DocValues来解决这一问题,它和 FieldCache 一样,都为列式存储,但它有如下优点:
- 预先构建,写入文件。
- 基于映射文件来做,脱离 JVM 堆内存,系统调度缺页。
DocValues 这种实现方法只比内存 FieldCache 慢大概 10~25%,但稳定性却得到了极大提升。
Lucene 目前有五种类型的 DocValues:NUMERIC、BINARY、SORTED、SORTED_SET、SORTED_NUMERIC,针对每种类型 Lucene 都有特定的压缩方法。
FieldCache 和 DocValue 的区别:
- FieldCache 不会在索引(写入数据)的时候创建,而是在查询运行时动态填充;并且 FieldCache 是存储在内存中的。
- DocValue 会在索引的时候写入磁盘(在索引时与倒排索引同时生成的,并且是不可变的,与倒排表一样,保存在 lucene 文件中(序列化到磁盘)),在使用字段聚合或者排序的时候可以从磁盘直接加载。
(这样看来,牺牲了部分写入的时间,但是获得了查询的高效)
范围查询的优化
没有 BKD 树的时候,Lucene 是如何对数值类型进行范围查询是下面这样的:
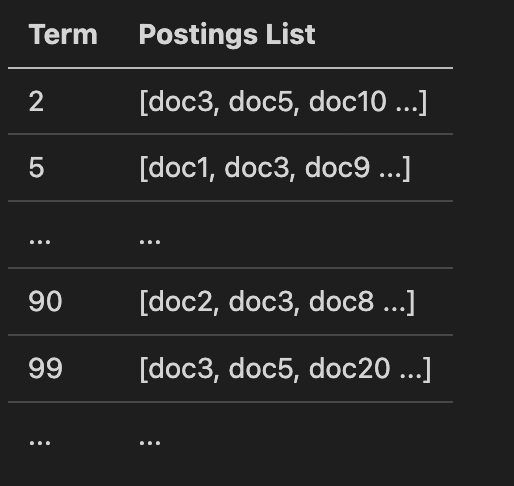
假设有上面的一个数值类型的倒排表,这种结构对于精确的数值查询速度还是比较快的,直接从倒排索引根据查找的 term 拿到 postings list 就好了。 但类似 range: [50, 100]这样的范围查找就比较麻烦了,Lucene 在找到对应的 term 后,只能将其转换成类似 50 OR 51 OR 52 … OR 100 这样的 Bool 查询。
可想而知,这个多条件 OR 查询开销很高,执行很慢。所以 Lucene 在创建索引的时候,会自动产生一些类似50x75 这样的特殊 Term,指向包含在该范围的文档列表,从而可以将查询优化成类似 50x75 OR 76x99 OR 100 这种形式。但是这种优化在字段的不同值很多,查询范围很大的时候,依然很无力。 因此早期版本的 Lucene 和 ES 的范围查询性能一直被诟病。
ES5 之后使用 Lucene6.0,Lucene6.0 对数字类型的范围查询优化,使用 BKD 树优化数值类型的范围查询。
具体参考:b-k-d 树 原理 图文解析_stevewongbuaa 的博客-CSDN 博客_bkd 树 和 number?keyword?傻傻分不清楚
下面看下 BKD 树是如何提高数字类型的范围查询的:
b-k-d 树(多维树)
用于多维度搜索的。例如在二维平面搜一个点,在三维空间搜一个点,在多维空间搜一个点。
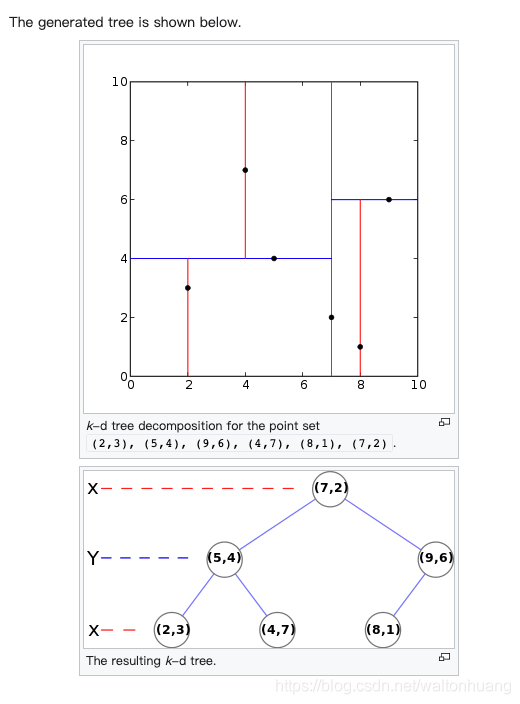
理论上 k-d 树可以继续到 4 维,5 维… 作为一个三维空间里的生物,就没法用图来展示这样的元素了 😅
第一级:按照 X 维度划分,划分点是(7,2),左子树都要在 X 维度比(7,2)小,也就是 x<7。也就是,左子树都在(7,2)这个点的左边。右子树都在(7,2)这个点的右边
第二级:按照 Y 维度划分,划分点是(5,4),他的左子树在 Y 维度上都要比(5,4)小,也就是 y<4
(想要查找年龄在 20 岁以上并且身高在 170 到 180 之间的所有人,用 B-K-D 树就能很好的解决。)
需要注意的是,因为数值型字段在 5.x 里没有采用倒排表索引, 而是以 value 为序,将 docid 切分到不同的 block 里面。对应的,数值型字段的 TermQuery 被转换为了 PointRangeQuery。这个 Query 利用 Block k-d tree 进行范围查找速度非常快,但是满足查询条件的 docid 集合在磁盘上并非向 Postlings list 那样按照 docid 顺序存放,也就无法实现 postings list 上借助跳表做蛙跳的操作。 要实现对 docid 集合的快速 advance 操作,只能将 docid 集合拿出来,做一些再处理。
所以对于 term 查询,不需要进行一些数值计算或者范围计算的字段最好都定义为 keyword。
Eagle 官方文档认为对于数值类型的大量 term 查询是一个 ES Bad Case,推荐使用 ES multi-field进行优化。