ES 和 lucene 的关系
- lucene: lucene 是一个 Java 信息检索程序库。可以类比为封装的底层 API,程序引用这个库之后可以使用其中的一些功能。
- ES: ES 是基于 lucene 这个包基础上进行构建的一个满足高可用、高性能、高可拓展的分布式存储中间件。
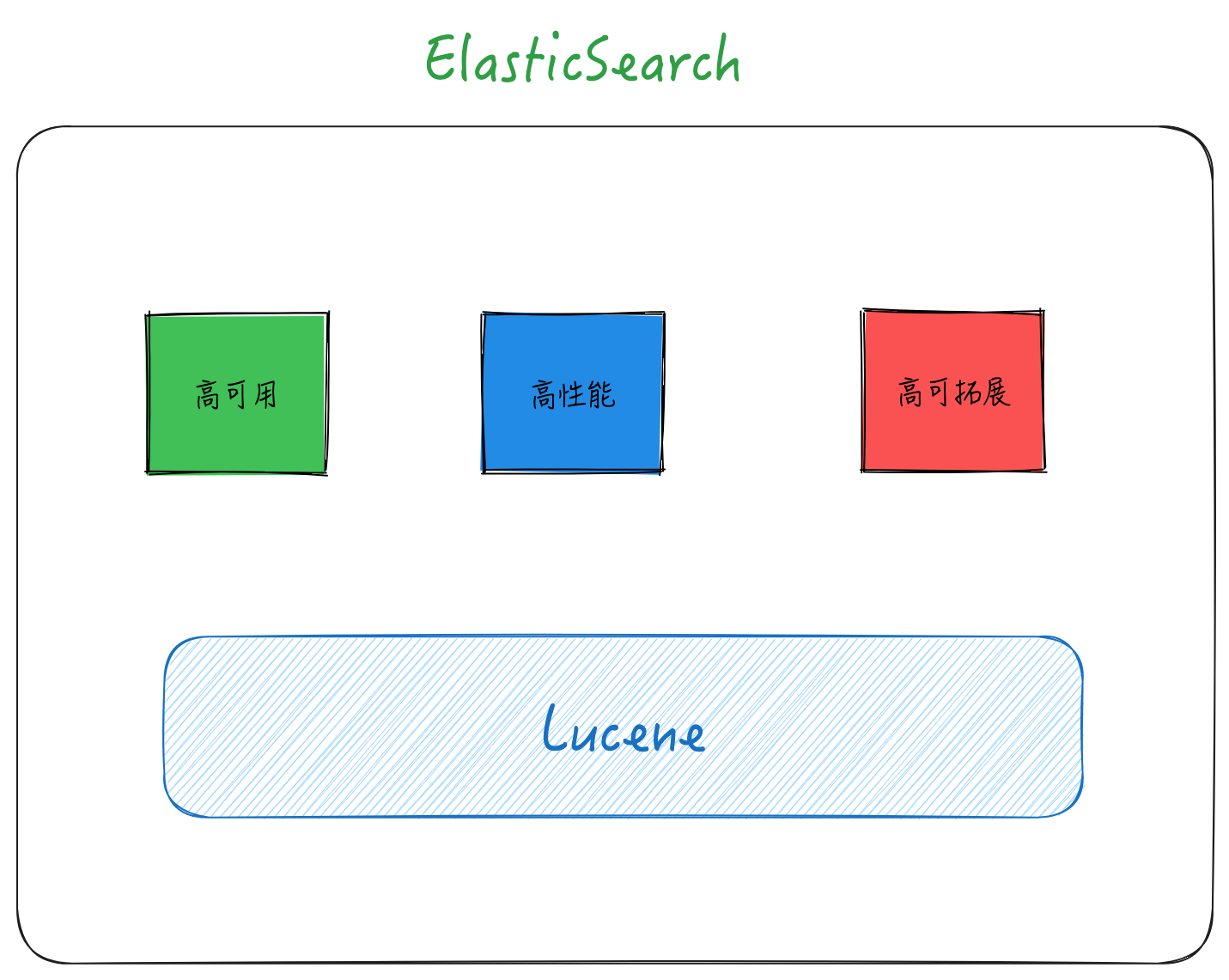
Lucene 的底层数据结构设计
Lucene 是一个高效的,基于 Java 的全文检索库。主要包括下面的一些核心操作:
倒排索引
什么是倒排索引?
首先看下什么是正排索引:
MySQL 中,根据 id 可以直接查找到数据行,那么 id 这个查询条件使用的就是正排索引;可以理解为,正排索引就是从文档 id 到文档内容映射。
那什么是倒排索引?
ES 将数据进行分词之后,存储到倒排索引中。分词之后会分成多个字符串值,倒排索引存储的就是这些字符串值到文档 id 的映射。可以理解为,倒排索引就是从字段到文档 id 的映射。
为什么使用倒排索引呢?倒排索引最后不也是拿到文档 id 进行查询文档,使用正排索引不是也能满足需求吗?
搜索引擎通常用于搜索网页内容,而网页内容多为文章。我们通常使用关键字来查询相关文章。由于文章内容较长,若使用 MySQL 数据库进行查询,需采用类似like %关键字%的方式,这种方式会导致全表扫描,查询性能极低。即便尝试构建索引,对文章内容进行索引也是不切实际的。
使用 Elasticsearch(ES)可以先对文章进行分词,然后将每个词项对应的倒排列表存入 ES 的倒排索引中。这样,通过关键字查找相关网页文章的速度就像哈希查找一样快,避免了线性全表扫描。ES 的倒排索引将非结构化的文章内容分词整理,转换成结构化的倒排列表存储,从而在进行关键字的全文索引时能达到极佳的效果。
电商搜索系统通常需要快速的查询响应速度,以确保良好的用户体验和较高的商品销量。通常,电商搜索系统,例如淘宝、京东、咸鱼、拼多多等,在进行商品搜索的时候,可以按照商品的名称进行模糊搜索,除此之外,还能对商品进行各种各样的筛选:分类、品牌、价格、特征、尺码、包装形式、是否折扣、发货地……
首先,为了保证搜索速度,是否应在 MySQL 中为各种筛选项添加索引是一个问题。如果添加索引,MySQL 的索引可能会过度膨胀,影响写入性能。相比之下,Elasticsearch(ES)默认所有字段都是索引,更适合处理多条件查询。此外,商品名称的模糊查询也不适合使用 MySQL。(MySQL 对于模糊查询最多做到前缀匹配)
在上述两个案例中,我们了解到在实际业务中,最终都需要获取文档 ID。关键在于如何高效地获取这些 ID,以及采用何种数据结构。MySQL 通过全表扫描来获取 ID,而 Elasticsearch(ES)则利用倒排索引快速检索 ID。两者的优劣显而易见。
这也说明了使用正排索引的局限:模糊查询和多条件筛选查询能力的欠缺。而这两个正是 ES 的强项。
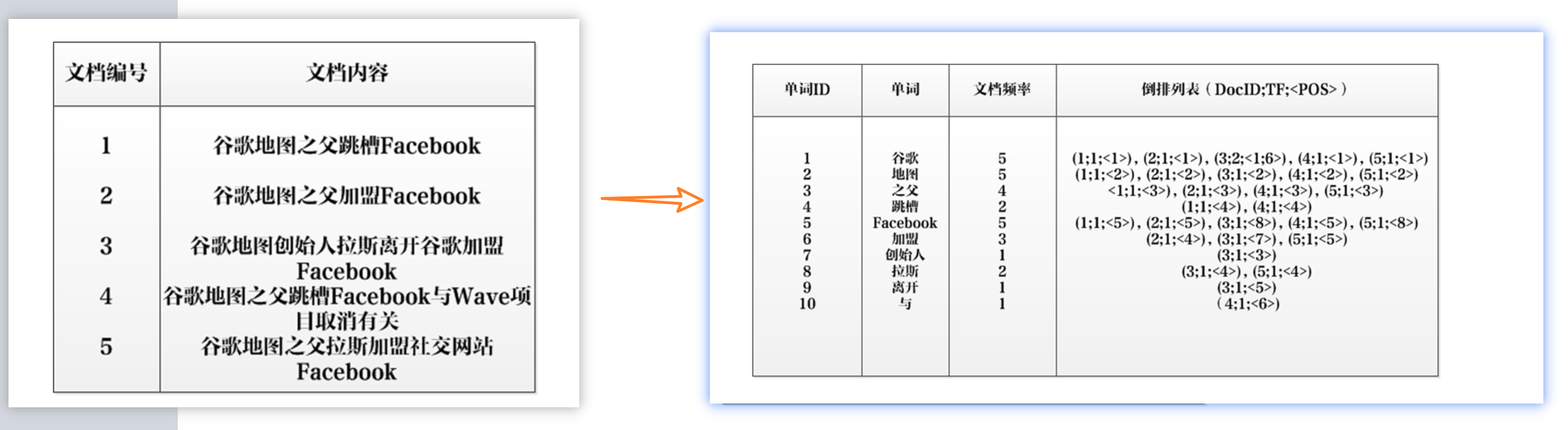
简单描述下倒排索引,下面是一个倒排索引进行构建的例子:
左图是一个正排索引,记录文档 id 到文档内容的映射;右图是倒排索引,记录了单词(由文档内容分词而成)到文档 id 的映射,每个单词有自己的单词 id,另外,倒排索引不仅记录了单词所在的文档 id,还记录了单词在文档出现的频率和出现在文档的单词次序(文档内容的第几个单词)。
词典-FST
很多人仅仅知道 ES 中的底层是倒排索引,其实 ES 的索引构建由词典和倒排表构成,其中词典结构尤为重要。
参考各种词典结构的优点和缺点(参考:Lucene 底层原理):
| 数据结构 | 优缺点 |
|---|---|
| 排序列表 Array/List | 优点:实现简单 缺点:不平衡;性能差,且依赖数据的顺序性 |
| HashMap/TreeMap | 优点:性能高,查询快 缺点:内存消耗大,几乎是原始数据的三倍 |
| Skip List(跳跃表) | 优点:可快速查找词语(在 lucene、redis、Hbase 等均有实现),相对于 TreeMap 等结构,特别适合高并发场景(Skip List 介绍)、占用内存小且可调 缺点:模糊查询支持不好。一般作为等值查询的索引 |
| Trie | 优点:适合英文词典,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的 trie 树将非常消耗内存 缺点:对于后缀搜索不友好 |
| Finite State Transducers (FST) | 一种有限状态转移机,Lucene 4 有开源实现,并大量使用。共享前缀,内存消耗少,但要求输入有序,更新不易 |
上面列出的一些词典的结构,最简单如排序数组,可以通过二分查找来检索数据;更快的有在内存直接使用的哈希表;磁盘查找有 B 树、B+树,其中 MySQL 是使用 B+树作为词典;而 Redis 使用跳跃表和哈希表等。
但一个能支持 TB 级数据的倒排索引结构需要在时间和空间上有个平衡,主要有如下的三种主要实现方式提供 ES 进行选择:
| 结构 | 图 | 优点 | 缺点 |
|---|---|---|---|
| B+树 | 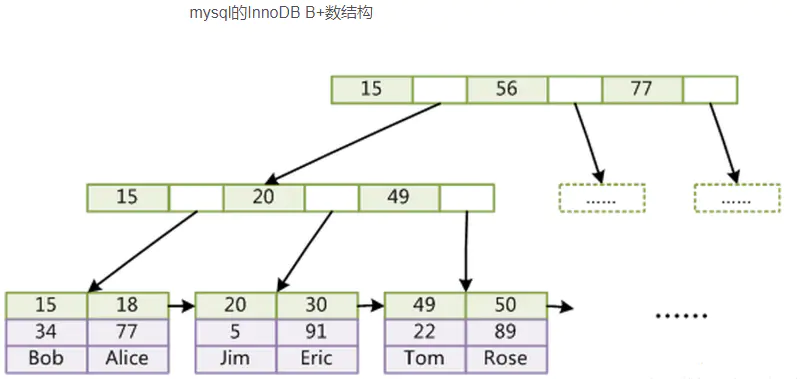 |
外存索引(在磁盘上)、可更新(在原来数据的基础上更新 | 占用空间大、速度不够快 |
| 跳跃表 | 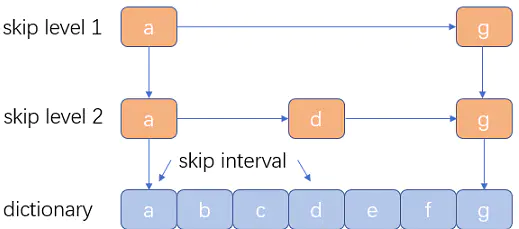 |
结构简单、跳跃间隔、级数可控。 (Lucene3.0 之前使用的也是跳跃表结构,后换成了 FST,但跳跃表在 Lucene 其他地方还有应用如倒排表合并和文档号索引。) |
模糊查询支持不好 |
| FST | 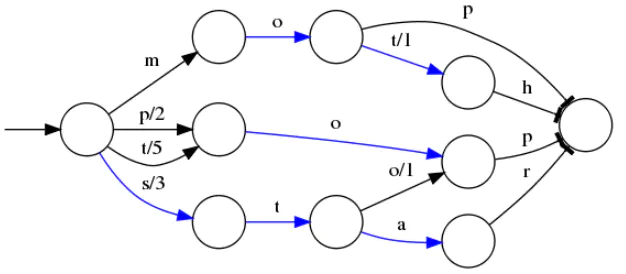 |
节省内存,查询快,支持前缀和后缀查询 | 更新难,构建复杂 |
lucene 从 4.x 开始大量使用的数据结构是 FST(Finite State Transducer,有限状态转换器)。FST 有两个优点:
- 空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间。
- 查询速度快。O(len(str))的查询时间复杂度。(str 是输入的查询字符串长度)
FST 类似一种 TRIE 树。但是和字典树有什么区别呢?参考:关于 Lucene 的词典 FST 深入剖析
假设我们有一个这样的 Set: mon,tues,thurs。FST 是这样的:
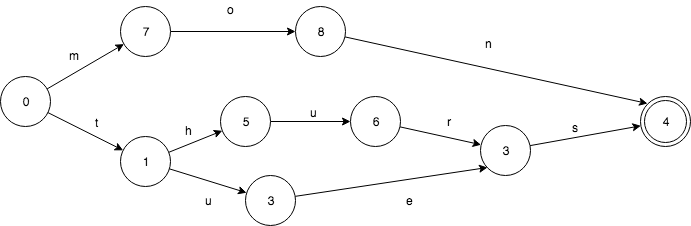
相应的 TRIE 则是这样的,只共享了前缀,如下图:
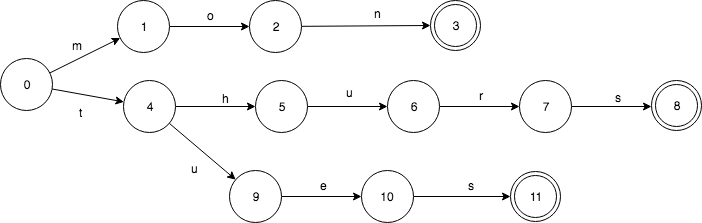
TRIE 有重复的 3 个 final 状态 3,8,11. 而 8,11 都是 s 转移,是可以合并的。
FST 支持后缀,字典树只支持前缀查询。
除了在 Term 词典这块有应用,FST 在整个 lucene 内部使用的也是很广泛的,基本把 hashmap 进行了替换。
ES 倒排索引实现细节
通过结合 FST 和倒排索引,我们可以得到下面这张 Lucene 对于倒排索引实现的大概结构:
假设查询 Allen,查询过程会先从 Term-Index 查询这个词在 Term Dictonary 的大概位置,及从 Ada 开始遍历查询,然后精确的查询到 Allen 的具体位置,得到倒排列表。
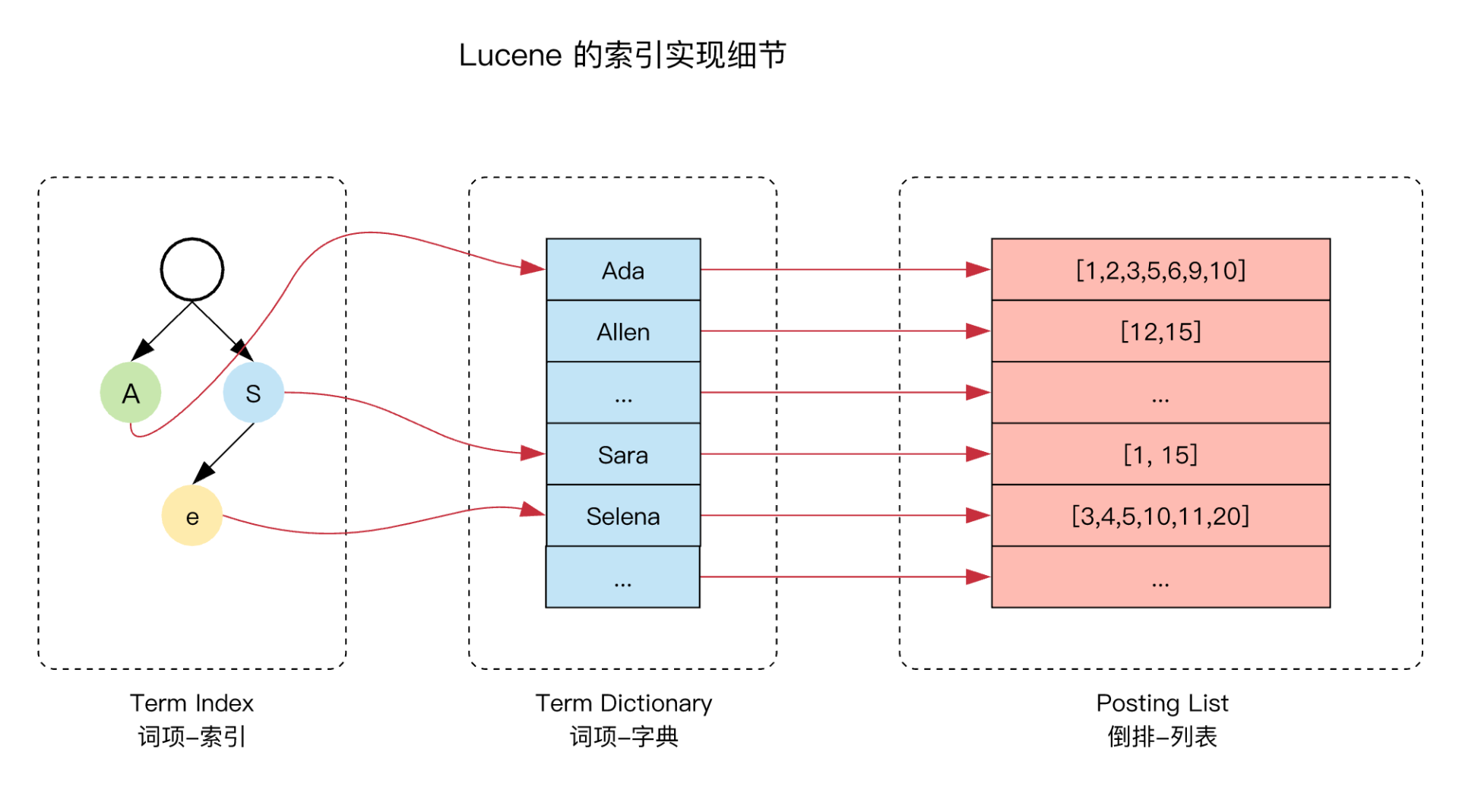
建立 FST 这个二级索引,可以实现倒排索引的快速定位,不需要经过多次的磁盘 IO,搜索效率大大提高了。不过需要注意的是 FST 是存储在堆内存中的,而且是常驻内存,大概占用 50%-70%的堆内存,因此这里也是我们在生产中可以进行堆内存优化的地方。
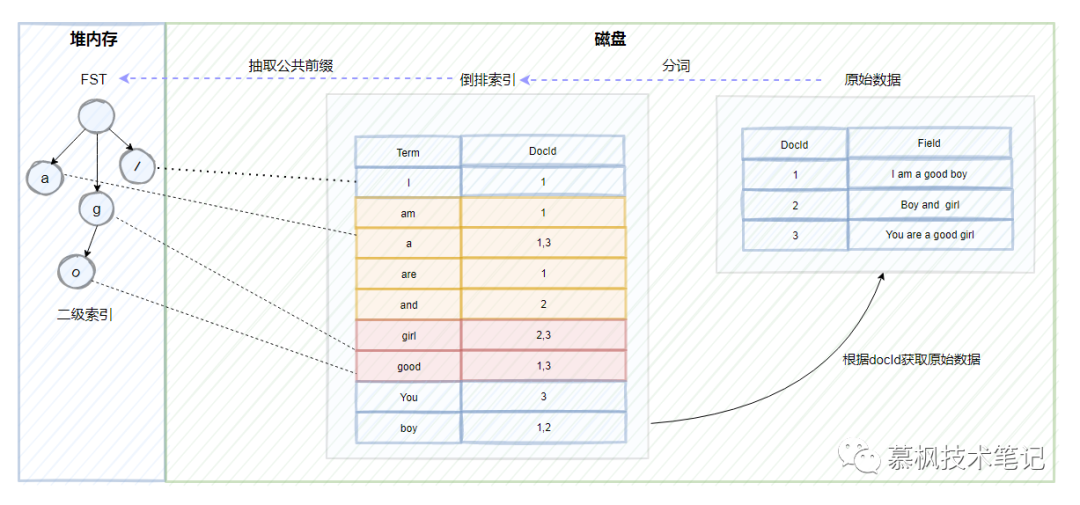
这个时候我们分析下“为什么 Elasticsearch/Lucene 检索可以比 mysql 快”(注意,这里说的是检索,并不是写入)
(实际上,ES 的写入因为需要构建许多结构化的数据,如倒排表、docValue 等,提供后续进行查找,并且还需要考虑分布式同步等操作,写入应该是会比 MySQL 慢 的,所以 ES 比较适合 OLAP)