AES算法是继DES之后比较快且比较简单的加密算法.⚖
对称加密
对称加密模型
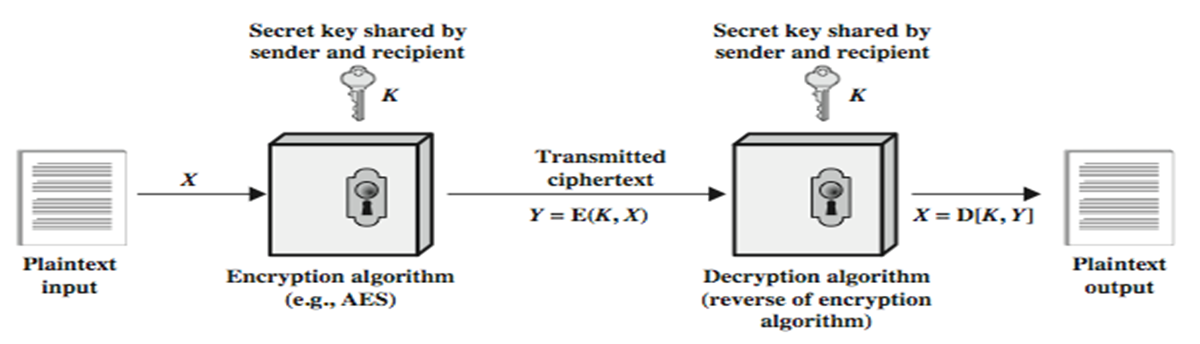
如下图,发送者和接收者共享一个一样的密钥,相当于现实生活中的锁,
对称加密的使用要求
加密算法是公开的,不需保密;并且解密算法本质上是加密算法的反向执行。
但是,如何安全的分发安全密钥呢?——————安全分发不可能单靠对称加密算法,常常使用的是非对称加密算法。
所以,对称加密的安全性取决于密钥的保密性而非算法的保密性,通常认为已知密文和加密/加密算法的基础上不能够破译信息。
AES算法
算法原理:
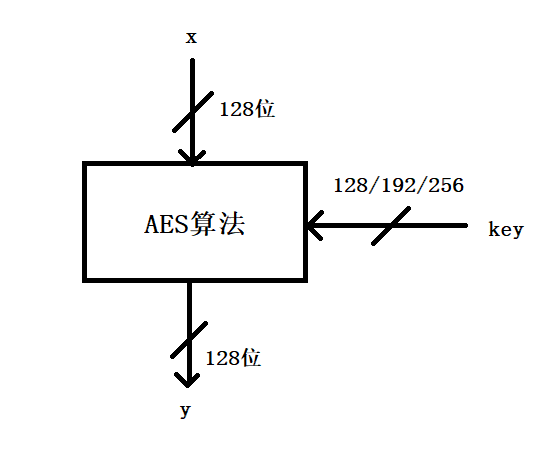
AES密码与分组密码Rijndael基本上完全一致,Rijndael分组大小和密钥大小都可以为128位、192位和256位。然而AES只要求分组大小为128位,因此只有分组长度为128Bit的Rijndael才称为AES算法。
下面是分组长度为128位的AES算法,而key位数可以是128/192/256,本次实验选择key的大小位128位.
特点
- 明文分组被描述为一个字节方阵并复制到状态数组,在每轮替换和移位时都并行处理整个状态分组。
- 矩阵中字节的顺序是按列排序的,例如128比特的明文分组的前4个字节占输入矩阵的第一列,接下来的4个字节占第二列,依次类推。扩展子密钥数组也类似操作。
- 假设AES使用128比特的密钥,其密钥被描述为一个字节方阵并将扩展成为一个子密钥数组w[i](具有44个32比特字),4个不同的字(共128比特)用作每轮的轮密钥。
- AES在每轮运算中将进行4个不同的步骤,1个是移位,3个是替换。
数学知识
在AES算法中的MixColumn层中会用到伽罗瓦域中的乘法运算,而伽罗瓦域的运算涉及一些数学知识。
素域
有限域有时也称伽罗瓦域,它指的是由有限个元素组成的集合,在这个集合内可以执行加、减、乘和逆运算。而在密码编码学中,我们只研究拥有有限个元素的域,也就是有限域。域中包含元素的个数称为域的阶。只有当m是一个素数幂时,即$m=p^n$(其中n为正整数是p的次数,p为素数),阶为m的域才存在。p称为这个有限域的特征。
例如,有限域中元素的个数可以是11(p=11是一个素数,n=1)、可以是81(p=3是一个素数,n=4)、也可以是256(p=2是一个素数,n=8)…..但有限域的中不可能拥有12个元素,因为12=2·2·3,因此12也不是一个素数幂。因此满足p是一个素数且满足$m = p^n$这个公式,m才是一个素数幂。
有限域中最直观的例子就是阶为素数的域,即n=1的域。域GF(p)的元素可以用整数0、1、…、p-1l来表示。域的两种操作就是模整数加法和整数乘法模p。加上p是一个素数,整数环Z表示为GF(p),也成为拥有素数个元素的素数域或者伽罗瓦域。GF(p)中所有的非零元素都存在逆元,GF(p)内所有的运算都是模p实现的。
素域内的算数运算规则如下
- 加法和乘法都是通过模p实现的;
- 任何一个元素a的加法逆元都是由a+(a的逆元)=0 mod p得到的;
- 任何一个非零元素a的乘法逆元定义为a·a的逆元=1。
举个例子,在素域GF(5)={0、1、2、3、4}中,2的加法逆元为3,这是因为2+(3)=5,5mod5=0,所以2+3=5mod5=0。2的乘法逆元为3,这是因为2·3=6,6mod5=1,所以2·3=6mod5=1。(在很多地方a的加法逆元用$-a$表示,a的乘法逆元用$1/a$表示)
注:GF(2)是一个非常重要的素域,也是存在的最小的有限域,由于GF(2)的加法,即模2加法与异或(XOR)门等价,GF(2)的乘法与逻辑与(AND)门等价,所以GF(2)对AES非常重要。
模2加法与异或(XOR)门等价:
$$
(1 + 0) \mod 2 = 1\\
(0 + 1) \mod 2 = 1\\
(0 + 0) \mod 2 = 0\\
(1 + 1) \mod 2 = 0\\
$$
乘法与逻辑与(AND)门等价:
$$
(1 \times 0) \mod 2 = 0\\
(0 \times 1) \mod 2 = 0\\
(0 \times 0) \mod 2 = 0\\
(1 \times 1) \mod 2 = 1\\
$$
扩展域
如果有限域的阶不是素数,则这样的有限域内的加法和乘法运算就不能用模整数加法和整数乘法模p表示。而且m>1的域被称为扩展域,为了处理扩展域,我们就要使用不同的符号表示扩展域内的元素,使用不同的规则执行扩展域内元素的算术运算。
在扩展域$GF(2^m)$中,元素并不是用整数表示的,而是用系数为域$GF(2)$中元素的多项式表示。这个多项式最大的度(幂)为m-1,所以每个元素共有m个系数,在AES算法使用的域$GF(2^8)$中,每个元素$A∈GF(2^8)$都可以表示为:
$$
A(x) = a_7x^7 + a_6x^6 + a_5x^5 + a_4x^4 + a_3x^3 + a_2x^2+a_1x + a_0,x_i \in GF(2) = 0,1
$$
注意:在域GF(2^8)中这样的多项式共有256个,这256个多项式组成的集合就是扩展域GF(2^8)。每个多项式都可以按一个8位项链的数值形式存储:
$$
A = (a_7,a_6,a_5,a_4,a_3,a_2,a_1,a_0)
$$
像$x^7$、$x^6$等因子都无需存储,因为从位的位置就可以清楚地判断出每个系数对应的幂。
扩展域$GF(2^m)$内的加减法
在AES算法中的密钥加法层中就使用了这部分的知识,但是不是很明显,因为我们通常把扩展域中的加法当作异或运算进行处理了,因为在扩展域中的加减法处理都是在底层域GF(2)内完成的,与按位异或运算等价。假设$A(x)$、$B(x)∈GF(2^m)$,计算两个元素之和的方法就是:
$$
C(x) = A(x) + B(x) = \sum_{i=0}^{m-1}C_ix^i , c_i = (a_i + b_i) \mod 2
$$
而两个元素之差的计算公式就是:
$$
C(x) = A(x) - B(x) = \sum_{i=0}^{m-1}C_ix^i , c_i = (a_i - b_i) \mod 2 = (a_i + b_i) \mod 2
$$
注:在减法运算中减号之所以变成加号,这就和二进制减法的性质有关了,大家可以试着验算下。从上述两个公式中我们发现在扩展域中加法和减法等价,并且与XOR等价(异或运算也被称作二进制加法)。
扩展域GF(2^m)内的乘法
扩展域的乘法主要运用在AES算法的列混淆层(Mix Column)中,也是列混淆层中最重要的操作。我们项要将扩展域中的两个元素用多项式形式展开,然后使用标准的多项式乘法规则将两个多项式相乘:
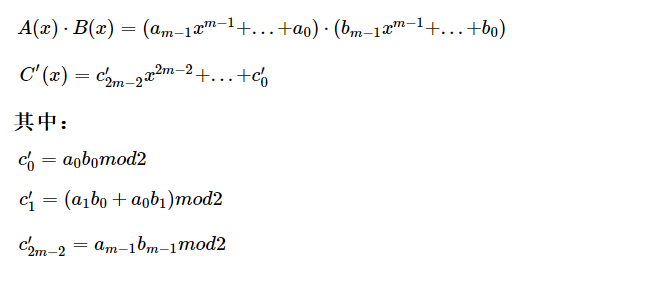
AES步骤详解
AES算法主要有四种操作处理,分别是密钥加法层(也叫轮密钥加,英文Add Round Key)、字节代换层(SubByte)、行位移层(Shift Rows)、列混淆层(Mix Column)。而明文x和密钥k都是由16个字节组成的数据(当然密钥还支持192位和256位的长度),它是按照字节的先后顺序从上到下、从左到右进行排列的。而加密出的密文读取顺序也是按照这个顺序读取的,相当于将数组还原成字符串的模样了,然后再解密的时候又是按照4·4数组处理的。AES算法在处理的轮数上只有最后一轮操作与前面的轮处理上有些许不同(最后一轮只是少了列混淆处理),在轮处理开始前还单独进行了一次轮密钥加的处理。在处理轮数上,只考虑128位密钥的10轮处理。
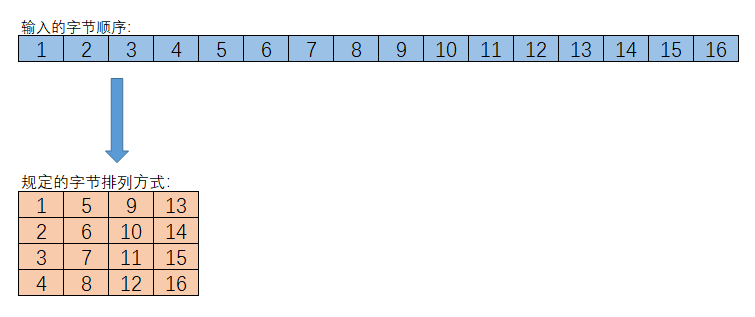
其中字节排列方式需要按照如下转换:
AES算法流程图如下:
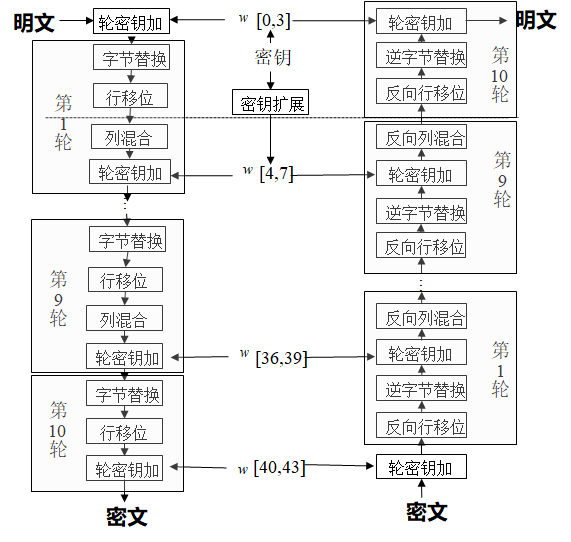
实现步骤及代码
按照AES流程图,对每一层的代码进行实现.
密钥加法层
在密钥加法层中有两个输入的参数,分别是明文和子密钥k[0],而且这两个输入都是128位的。在扩展域中加减法操作和异或运算等价,所以这里的处理也就异常的简单了,只需要将两个输入的数据进行按字节异或操作就会得到运算的结果。
如下图:
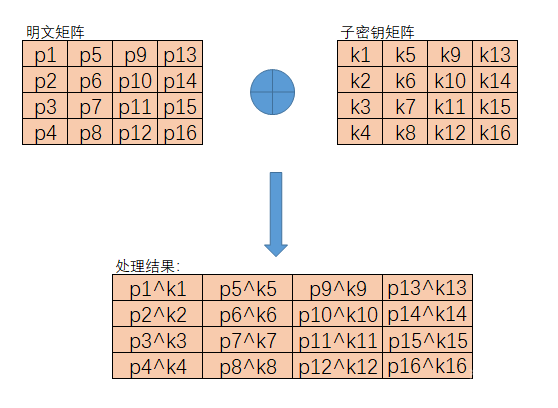
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
//轮密钥加变换 - 将每一列与扩展密钥进行异或
void AddRoundKey(byte mtx[4 * 4], word k[4])
{
for (int i = 0; i < 4; ++i)
{
word k1 = k[i] >> 24;
word k2 = (k[i] << 8) >> 24;
word k3 = (k[i] << 16) >> 24;
word k4 = (k[i] << 24) >> 24;
mtx[i] = mtx[i] ^ byte(k1.to_ulong());
mtx[i + 4] = mtx[i + 4] ^ byte(k2.to_ulong());
mtx[i + 8] = mtx[i + 8] ^ byte(k3.to_ulong());
mtx[i + 12] = mtx[i + 12] ^ byte(k4.to_ulong());
}
}
|
AES密钥生成
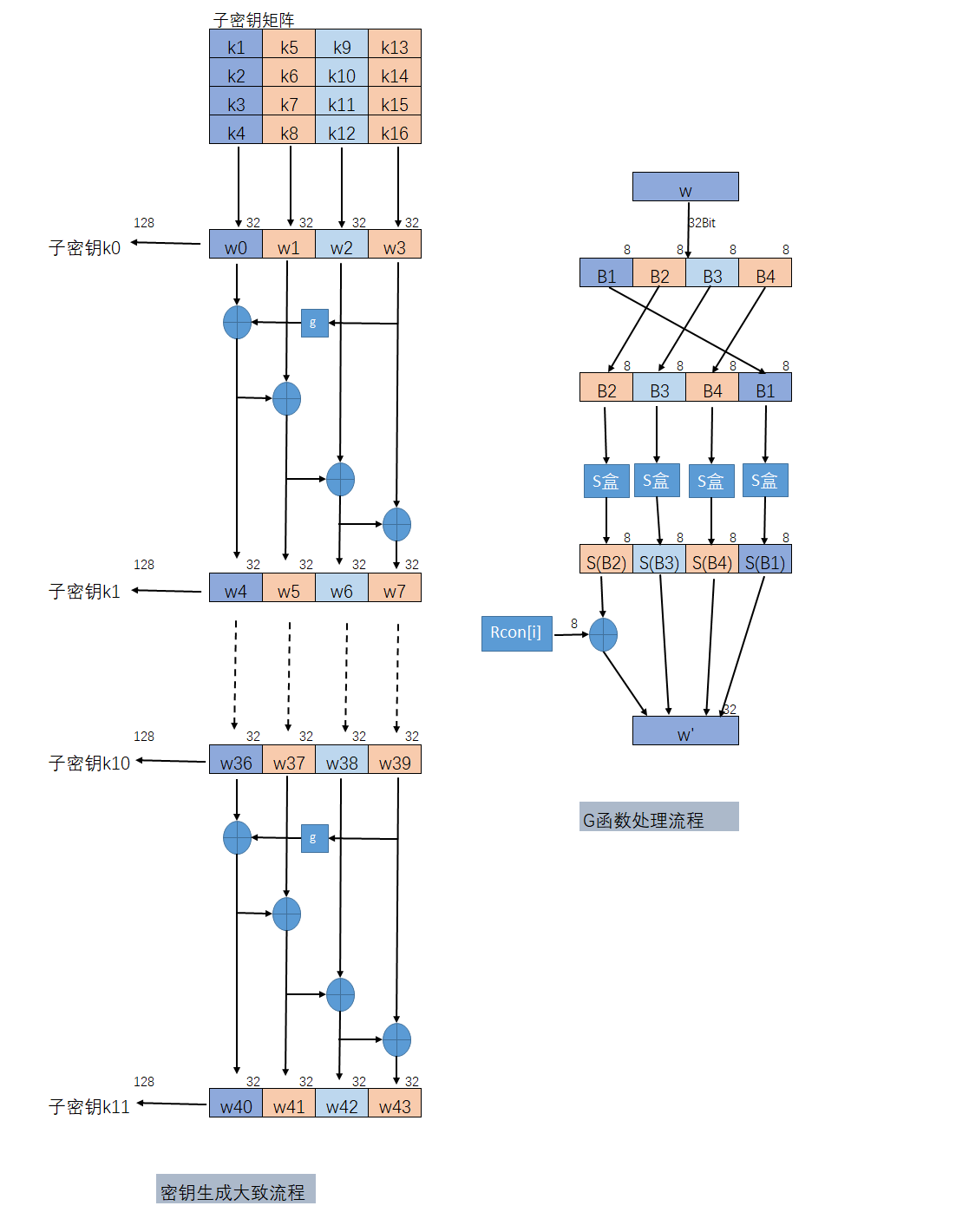
首先定义位置变换函数RotWord(),作用是接受一个字 $[a0, a1, a2, a3] $作为输入,循环左移一个字节后输出$ [a1, a2, a3, a0]$,代码如下:
1
2
3
4
5
6
|
word RotWord(const word &w)
{
word result(0x0);
result = (w << 8) | (w >> 24);
return result;
}
|
定义S盒变换函数SubWord(),接受一个字 $[a0, a1, a2, a3]$ 作为输入,然后每一个byte,例如a0,前四个字节为行,后四个字节为列,从S_Box中查找并且返回四个元素。,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
word SubWord(const word& sw)
{
word temp;
for(int i=0; i<32; i+=8)
{
int row = sw[i+7]*8 + sw[i+6]*4 + sw[i+5]*2 + sw[i+4];
int col = sw[i+3]*8 + sw[i+2]*4 + sw[i+1]*2 + sw[i];
byte val = S_Box[row][col];
for(int j=0; j<8; ++j)
temp[i+j] = val[j];
}
return temp;
}
|
轮常数Rcon[]作为一个常量数组,每一轮生成密钥的时候需要作为参数异或
1
2
3
|
// 轮常数,密钥扩展中用到。(AES-128只需要10轮)
word Rcon[10] = {0x01000000, 0x02000000, 0x04000000, 0x08000000, 0x10000000,
0x20000000, 0x40000000, 0x80000000, 0x1b000000, 0x36000000};
|
密钥拓展函数KeyExpansion(),接受一个参数为外部密钥,另外一个为需要拓展的轮密钥数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
//密钥扩展函数 - 对128位密钥进行扩展得到 w[4*(Nr+1),Nr为轮数
void KeyExpansion(byte key[4 * N_key], word w[4 * (N_round + 1)])
{
word temp;
int i = 0;
while (i < N_key) //前四个word就是输入的key
{
w[i] = ToWord(key[4 * i], key[4 * i + 1], key[4 * i + 2], key[4 * i + 3]);
++i;
}
i = N_key;
while (i < 4 * (N_round + 1))
{
temp = w[i - 1]; //记录前一个word
if (i % N_key == 0)
{ //temp先位置表换RotWord,再S盒变换,然后与轮常数异或,最后w[i-N_key] 异或
w[i] = w[i - N_key] ^ SubWord(RotWord(temp)) ^ Rcon[i / N_key - 1];
}
else
{
w[i] = w[i - N_key] ^ temp;
}
i++;
}
}
|
字节替换层
S盒字节替换,主要功能就是让输入的数据通过S_box表完成从一个字节到另一个字节的映射,读取S_box数据的方法就是要将输入数据的每个字节的高四位作为第一个下标,第四位作为第二个下标。然后返回数据,字节替换主要是为了扰乱数据。
S盒:
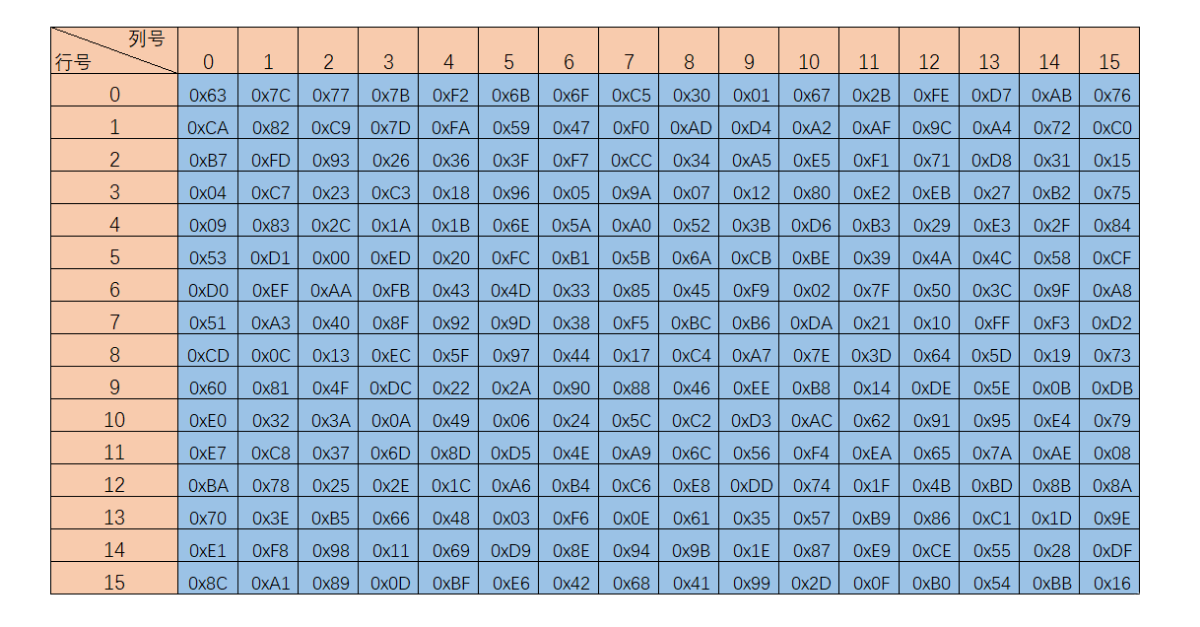
逆S盒:
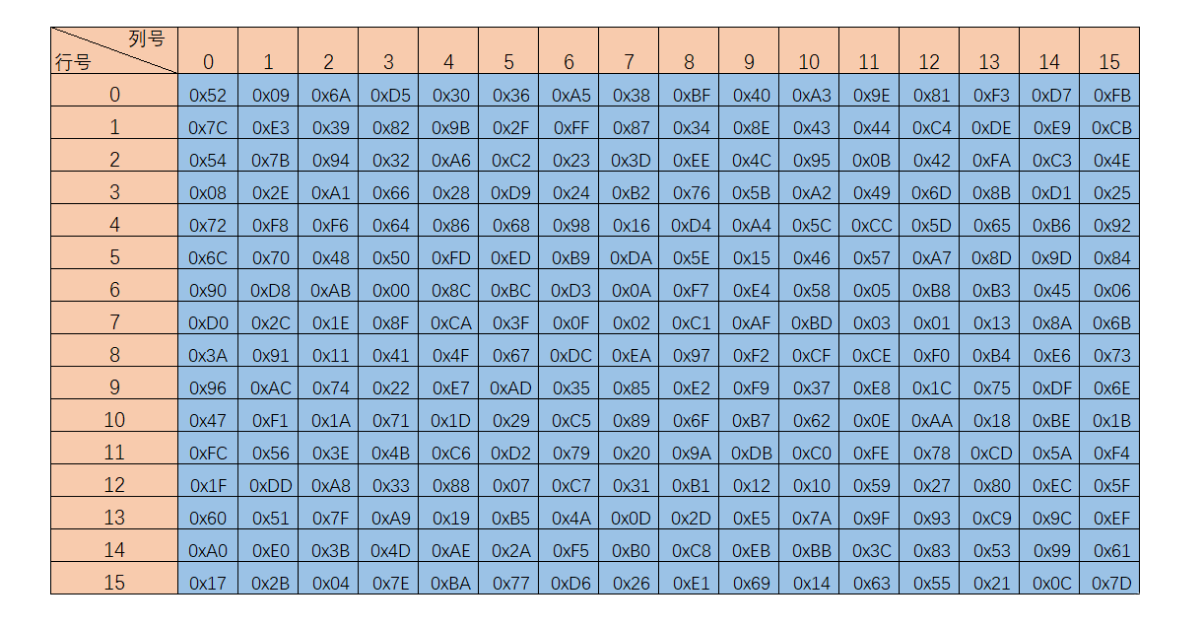
图解如下:
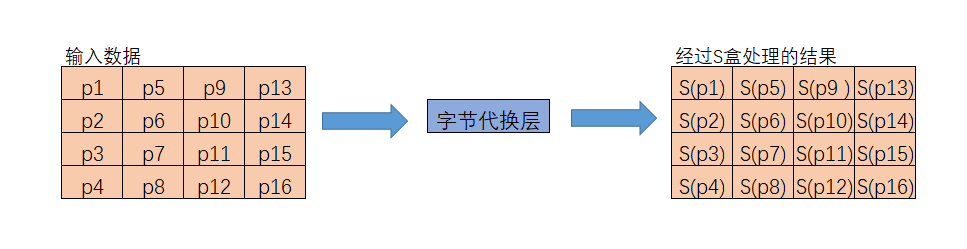
正向S盒变换代码如下:
1
2
3
4
5
6
7
8
9
10
|
//S盒变换 - 前4位为行号,后4位为列号
void SubBytes(byte mtx[4 * 4])
{
for (int i = 0; i < 16; ++i)
{
int row = mtx[i][7] * 8 + mtx[i][6] * 4 + mtx[i][5] * 2 + mtx[i][4];
int col = mtx[i][3] * 8 + mtx[i][2] * 4 + mtx[i][1] * 2 + mtx[i][0];
mtx[i] = S_Box[row][col];
}
}
|
反向S盒变换代码如下:
1
2
3
4
5
6
7
8
9
10
|
// 逆S盒变换
void InvSubBytes(byte mtx[4*4])
{
for(int i=0; i<16; ++i)
{
int row = mtx[i][7]*8 + mtx[i][6]*4 + mtx[i][5]*2 + mtx[i][4];
int col = mtx[i][3]*8 + mtx[i][2]*4 + mtx[i][1]*2 + mtx[i][0];
mtx[i] = Inv_S_Box[row][col];
}
}
|
行移位层
将输入数据作为一个$4·4$的字节矩阵进行处理,然后将这个矩阵的字节进行位置上的置换。在加密时行位移处理与解密时的处理相反,我们这里将解密时的处理称作逆行位移。它之所以称作行位移,是因为它只在$4·4$矩阵的行间进行操作,每行4字节的数据。在加密时,保持矩阵的第一行不变,第二行向左移动8Bit(一个字节)、第三行向左移动2个字节、第四行向左移动3个字节。而在解密时恰恰相反,依然保持第一行不变,将第二行向右移动一个字节、第三行右移2个字节、第四行右移3个字节。最终结束。
正向行移位图解:

代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
//正向行变换 - 按字节循环移位
void ShiftRows(byte mtx[4 * 4])
{
// 第二行循环左移一位
byte temp = mtx[4];
for (int i = 0; i < 3; ++i)
mtx[i + 4] = mtx[i + 5];
mtx[7] = temp;
// 第三行循环左移两位
for (int i = 0; i < 2; ++i)
{
temp = mtx[i + 8];
mtx[i + 8] = mtx[i + 10];
mtx[i + 10] = temp;
}
// 第四行循环左移三位
temp = mtx[15];
for (int i = 3; i > 0; --i)
mtx[i + 12] = mtx[i + 11];
mtx[12] = temp;
}
|
反向行移位图解:

代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 逆行变换 - 以字节为单位循环右移
void InvShiftRows(byte mtx[4*4])
{
// 第二行循环右移一位
byte temp = mtx[7];
for(int i=3; i>0; --i)
mtx[i+4] = mtx[i+3];
mtx[4] = temp;
// 第三行循环右移两位
for(int i=0; i<2; ++i)
{
temp = mtx[i+8];
mtx[i+8] = mtx[i+10];
mtx[i+10] = temp;
}
// 第四行循环右移三位
temp = mtx[12];
for(int i=0; i<3; ++i)
mtx[i+12] = mtx[i+13];
mtx[15] = temp;
}
|
列混淆层
列混淆子层是AES算法中最为复杂的部分,属于扩散层,列混淆操作是AES算法中主要的扩散元素,它混淆了输入矩阵的每一列,使输入的每个字节都会影响到4个输出字节。行位移子层和列混淆子层的组合使得经过三轮处理以后,矩阵的每个字节都依赖于16个明文字节成可能。
在加密的正向列混淆中,我们要将输入的$4·4$矩阵左乘一个给定的$4·4$矩阵。而它们之间的加法、乘法都在扩展域$GF(2^8)$中进行,,在矩阵相乘计算中,出现了加法和乘法,而前面提到了在拓展域中加法等同于异或运算,而对于乘法,需要特殊的方式进行处理,于是将+号换成^号,然后将伽罗瓦域的乘法定义成一个有两个参数的函数,并让他返回最后计算结果,最后列混淆代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
//正向列变换
void MixColumns(byte mtx[4*4])
{
byte arr[4];
for(int i=0; i<4; ++i)
{
for(int j=0; j<4; ++j)
arr[j] = mtx[i+j*4];
mtx[i] = GFMul(0x02, arr[0]) ^ GFMul(0x03, arr[1]) ^ arr[2] ^ arr[3];
mtx[i+4] = arr[0] ^ GFMul(0x02, arr[1]) ^ GFMul(0x03, arr[2]) ^ arr[3];
mtx[i+8] = arr[0] ^ arr[1] ^ GFMul(0x02, arr[2]) ^ GFMul(0x03, arr[3]);
mtx[i+12] = GFMul(0x03, arr[0]) ^ arr[1] ^ arr[2] ^ GFMul(0x02, arr[3]);
}
}
|
在解密的逆向列混淆中与正向列混淆的不同之处在于使用的左乘矩阵不同,它与正向列混淆的左乘矩阵互为逆矩阵,也就是说,数据矩阵同时左乘这两个矩阵后,数据矩阵不会发生任何变化。下面是图解:
正向混淆处理:
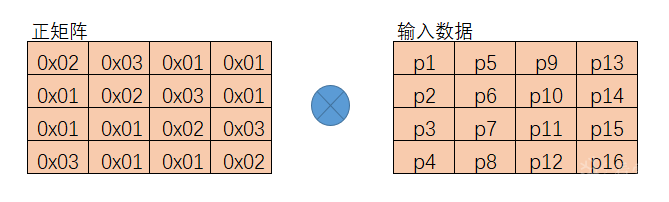
逆向混淆处理:
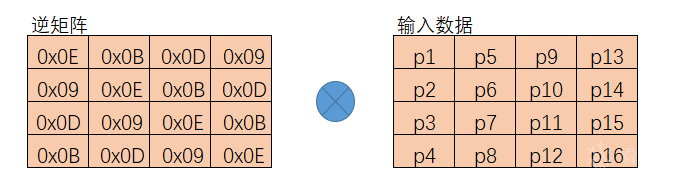
反向列变换代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
//反向列混淆
void InvMixColumns(byte mtx[4*4])
{
byte arr[4];
for(int i=0; i<4; ++i)
{
for(int j=0; j<4; ++j)
arr[j] = mtx[i+j*4];
mtx[i] = GFMul(0x0e, arr[0]) ^ GFMul(0x0b, arr[1]) ^ GFMul(0x0d, arr[2]) ^ GFMul(0x09, arr[3]);
mtx[i+4] = GFMul(0x09, arr[0]) ^ GFMul(0x0e, arr[1]) ^ GFMul(0x0b, arr[2]) ^ GFMul(0x0d, arr[3]);
mtx[i+8] = GFMul(0x0d, arr[0]) ^ GFMul(0x09, arr[1]) ^ GFMul(0x0e, arr[2]) ^ GFMul(0x0b, arr[3]);
mtx[i+12] = GFMul(0x0b, arr[0]) ^ GFMul(0x0d, arr[1]) ^ GFMul(0x09, arr[2]) ^ GFMul(0x0e, arr[3]);
}
}
|
密钥加法层
这一层主要是明文矩阵盒子密钥矩阵进行异或操作,在密钥加法层中有两个输入的参数,分别是明文和子密钥,而且这两个输入都是128位的。只需要将两个输入的数据进行按字节异或操作就会得到运算的结果。
图解:
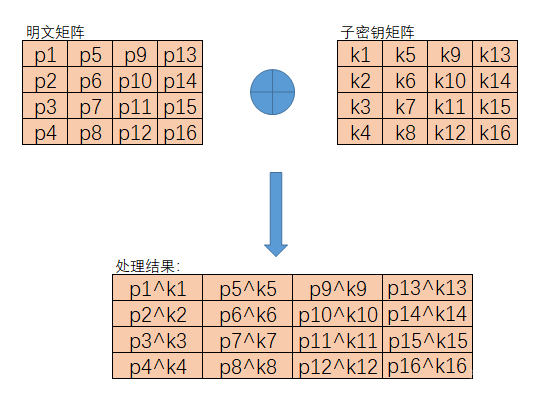
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
//轮密钥加变换 - 将每一列与扩展密钥进行异或
void AddRoundKey(byte mtx[4*4], word k[4])
{
for(int i=0; i<4; ++i)
{
word k1 = k[i] >> 24;
word k2 = (k[i] << 8) >> 24;
word k3 = (k[i] << 16) >> 24;
word k4 = (k[i] << 24) >> 24;
mtx[i] = mtx[i] ^ byte(k1.to_ulong());
mtx[i+4] = mtx[i+4] ^ byte(k2.to_ulong());
mtx[i+8] = mtx[i+8] ^ byte(k3.to_ulong());
mtx[i+12] = mtx[i+12] ^ byte(k4.to_ulong());
}
}
|
实现加密函数
加密函数按照流程图,首先开始是先进行一次轮密钥加,然后开始9轮的字节替换+行移位+列混淆+轮密钥加的操作,循环之后再做一次字节替换+行移位+轮密钥加就完成加密操作了.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
void encrypt(byte in[4*4], word w[4*(N_round+1)])
{
word key[4];
for(int i=0; i<4; ++i)
key[i] = w[i];
AddRoundKey(in, key);
for(int round=1; round<N_round; ++round)
{
SubBytes(in);
ShiftRows(in);
MixColumns(in);
for(int i=0; i<4; ++i)
key[i] = w[4*round+i];
AddRoundKey(in, key);
}
SubBytes(in);
ShiftRows(in);
for(int i=0; i<4; ++i)
key[i] = w[4*N_round+i];
AddRoundKey(in, key);
}
|
实现解密函数
解密函数与加密差不多,只不过将行移位变成反向行移位,列混淆变成反向列混淆,字节替换变成逆字节替换即可.
代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
void decrypt(byte in[4*4], word w[4*(N_round+1)])
{
word key[4];
for(int i=0; i<4; ++i)
key[i] = w[4*N_round+i];
AddRoundKey(in, key);
for(int round=N_round-1; round>0; --round)
{
InvShiftRows(in);
InvSubBytes(in);
for(int i=0; i<4; ++i)
key[i] = w[4*round+i];
AddRoundKey(in, key);
InvMixColumns(in);
}
InvShiftRows(in);
InvSubBytes(in);
for(int i=0; i<4; ++i)
key[i] = w[i];
AddRoundKey(in, key);
}
|
测试加密解密函数
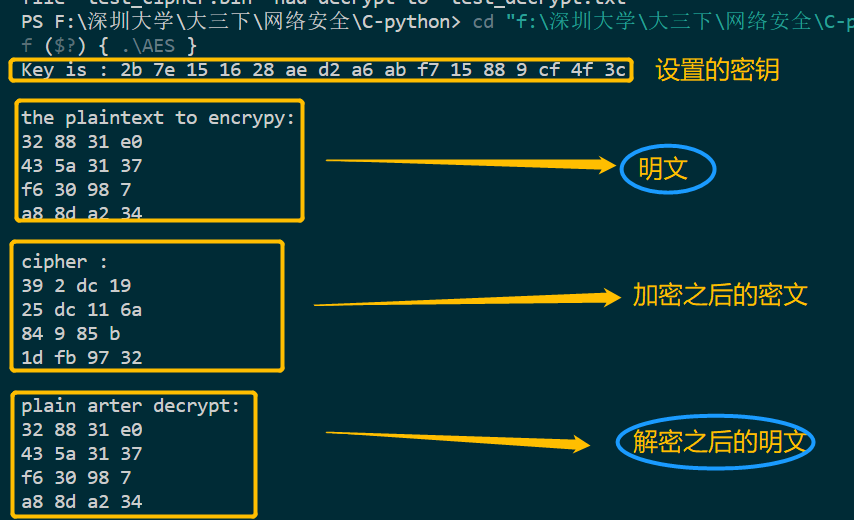
可以发现上面面的测试中明文与解密之后的明文是完全正确的,说明加密函数与解密函数正确!
测试代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
void Aes_test()
{
byte key[16] = {0x2b, 0x7e, 0x15, 0x16,
0x28, 0xae, 0xd2, 0xa6,
0xab, 0xf7, 0x15, 0x88,
0x09, 0xcf, 0x4f, 0x3c};
byte plain[16] = {0x32, 0x88, 0x31, 0xe0,
0x43, 0x5a, 0x31, 0x37,
0xf6, 0x30, 0x98, 0x07,
0xa8, 0x8d, 0xa2, 0x34};
// 输出密钥
cout << "Key is : ";
for (int i = 0; i < 16; ++i)
cout << hex << key[i].to_ulong() << " ";
cout << endl;
word w[4 * (N_round + 1)];
KeyExpansion(key, w);
// 输出待加密的明文
cout << endl
<< "the plaintext to encrypy:" << endl;
for (int i = 0; i < 16; ++i)
{
cout << hex << plain[i].to_ulong() << " ";
if ((i + 1) % 4 == 0)
cout << endl;
}
cout << endl;
// 加密,输出密文
encrypt(plain, w);
cout << "cipher : " << endl;
for (int i = 0; i < 16; ++i)
{
cout << hex << plain[i].to_ulong() << " ";
if ((i + 1) % 4 == 0)
cout << endl;
}
cout << endl;
// 解密,输出明文
decrypt(plain, w);
cout << "plain arter decrypt:" << endl;
for (int i = 0; i < 16; ++i)
{
cout << hex << plain[i].to_ulong() << " ";
if ((i + 1) % 4 == 0)
cout << endl;
}
cout << endl;
}
|
实现加解密文件
加密文件函数,返回加密后的文件名:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
string encryptFile(string oname, string suffix, word w[4 * (N_round + 1)])
{
string outputfilename = oname + "_cipher.bin";
bitset<128> data;
byte plain[16];
cout << "begining encrypy..........." << endl;
clock_t start = clock();
// 将文件加密到 oname + cipher.bin 中
ifstream in;
ofstream out;
in.open(oname + suffix, ios::binary); //输入文件
out.open(outputfilename, ios::binary); //输出加密文件
while (in.read((char *)&data, sizeof(data)))
{
divideToByte(plain, data);
encrypt(plain, w);
data = mergeByte(plain);
out.write((char *)&data, sizeof(data));
data.reset(); // 置0
}
in.close();
out.close();
clock_t end = clock();
cout << "encrypy finish!" << endl;
cout << "encrypy cost time : " << (end - start) << " ms" << endl;
return outputfilename; //返回加密之后的文件
}
|
解密文件函数,返回解密后的文件名:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
string decryptFile(string filename, string oname, string suffix, word w[4 * (N_round + 1)])
{
ifstream in;
ofstream out;
in.open(filename, ios::binary);
string outputfilename = oname + "_decrypt" + suffix;
out.open(outputfilename, ios::binary);
bitset<128> data;
byte plain[16];
cout << "begining decrypt............" << endl;
clock_t start = clock();
while (in.read((char *)&data, sizeof(data)))
{
divideToByte(plain, data);
decrypt(plain, w);
data = mergeByte(plain);
out.write((char *)&data, sizeof(data));
data.reset(); // 置0
}
in.close();
out.close();
clock_t end = clock();
cout << "decrypt finish!" << endl;
cout << "decrypt cost time : " << end - start << " ms" << endl;
return outputfilename;
}
|
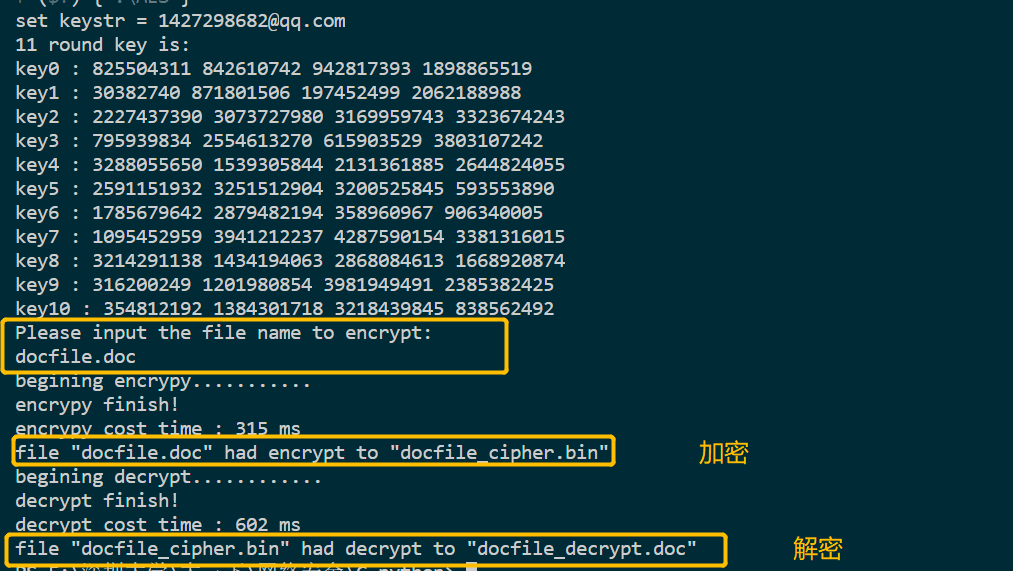
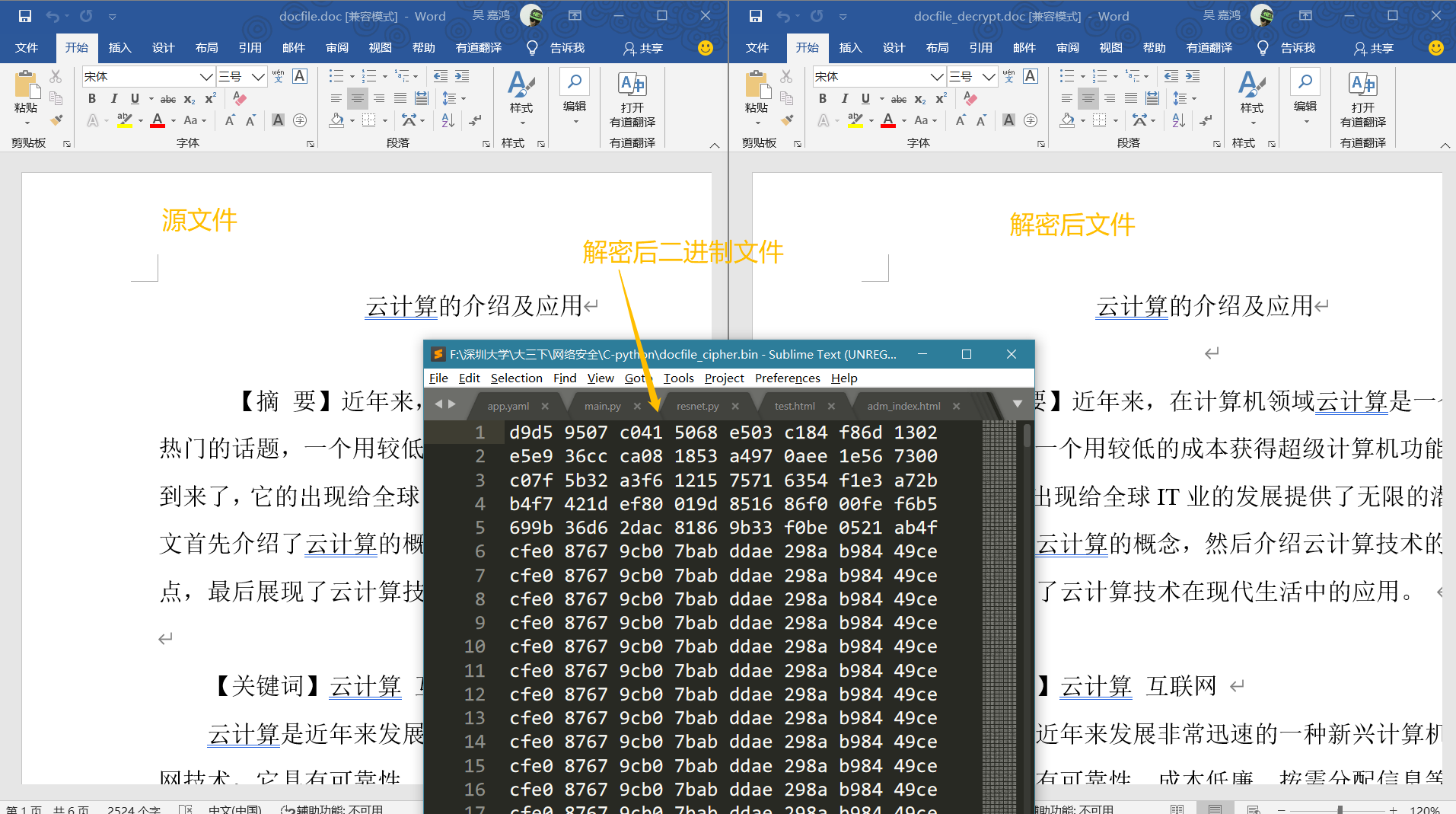
实现效果:
加密txt文件:
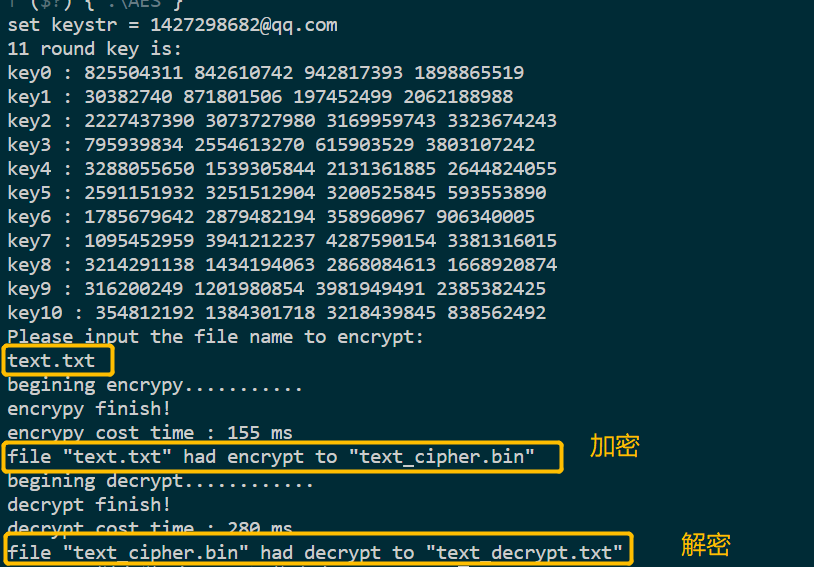
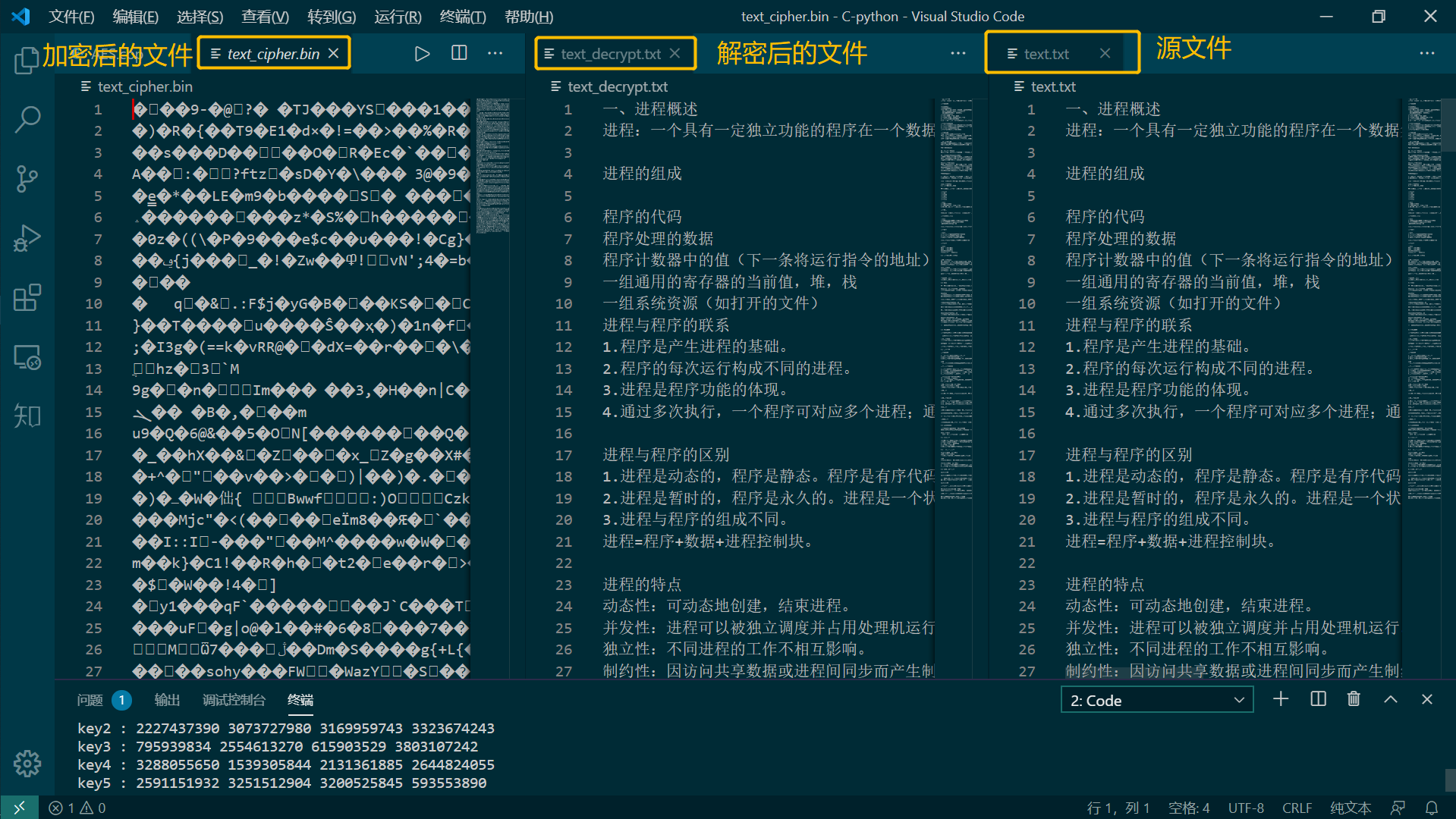
加密jpg文件:
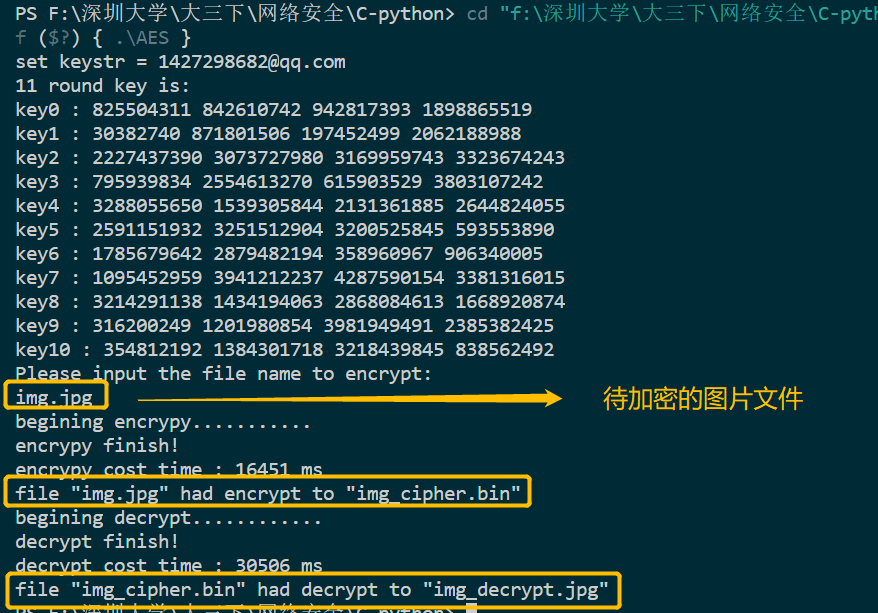
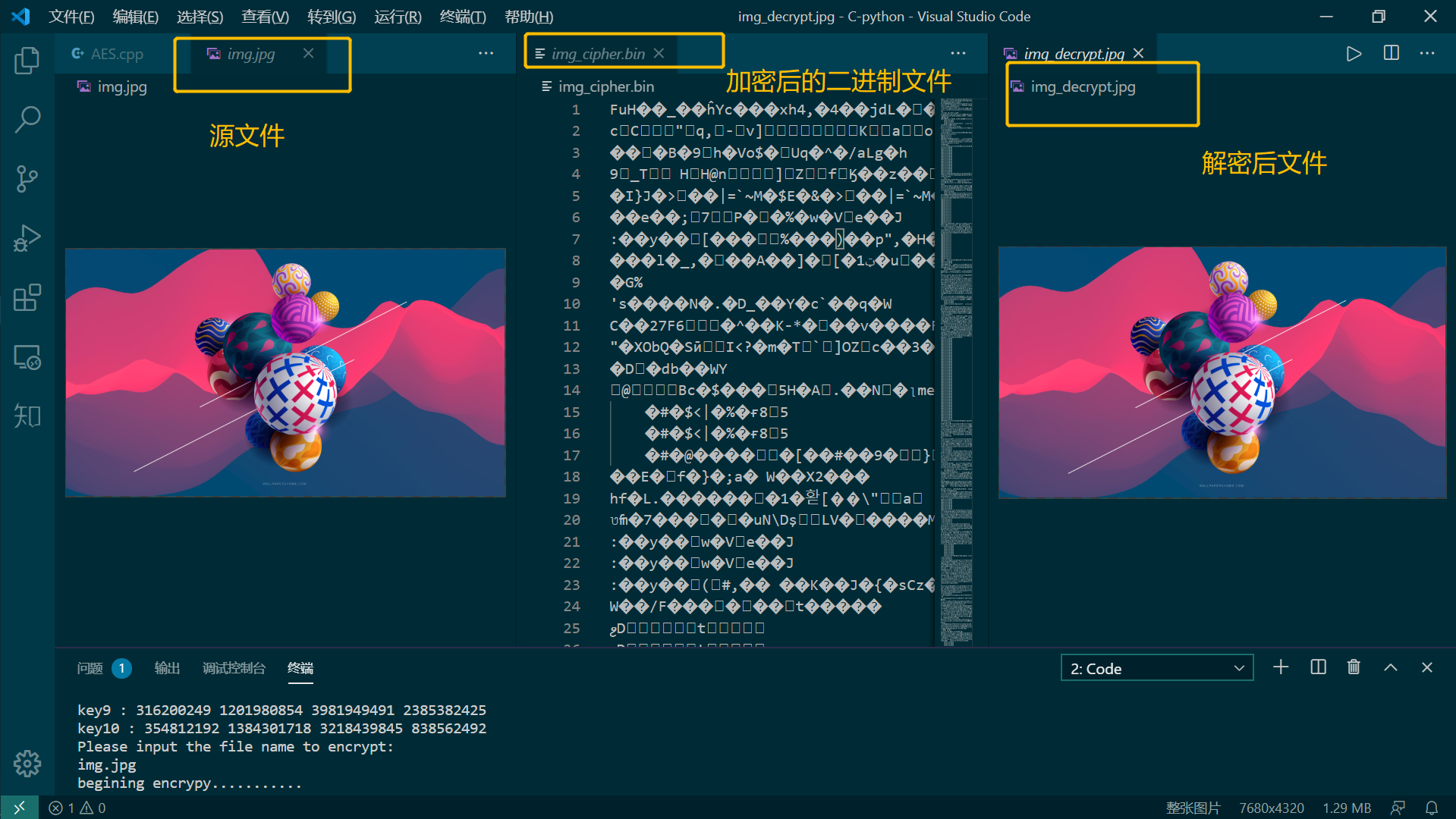
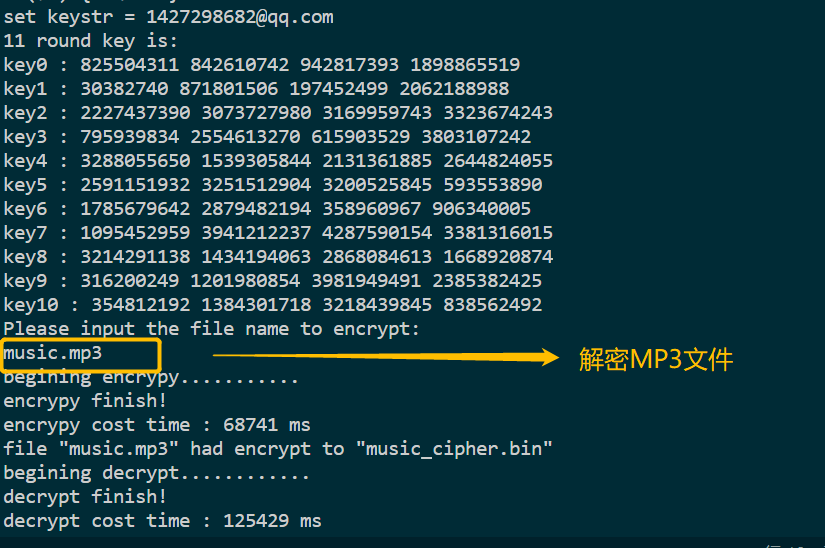
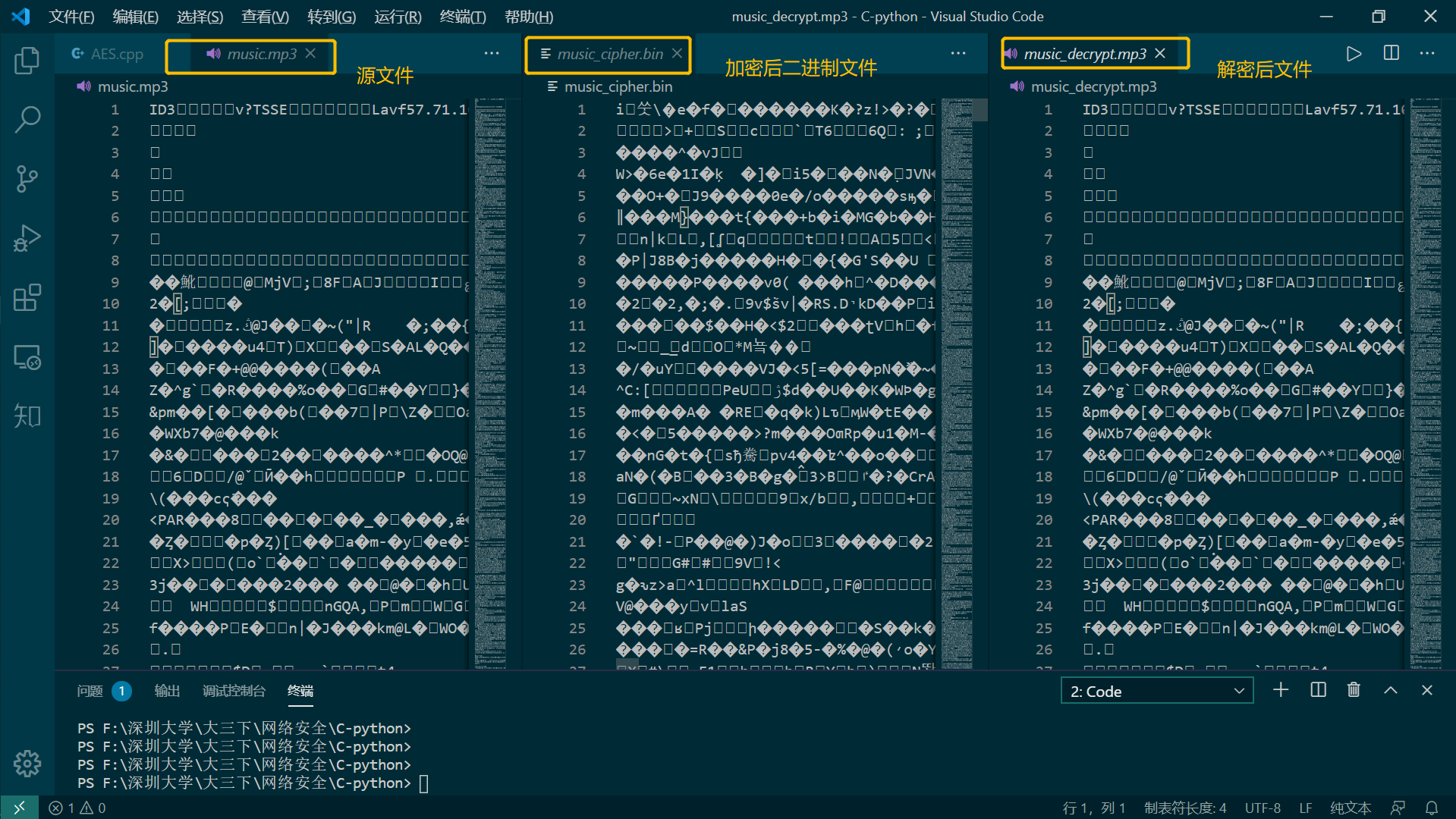
加密mp3文件:
加密doc文件:
AES五种加密模式
实现五种加密方式的密钥是一个置换表unsigned char Table[4] = {0x12, 0xb1, 0x53, 0x28};,加密函数是原文与密钥的异或.
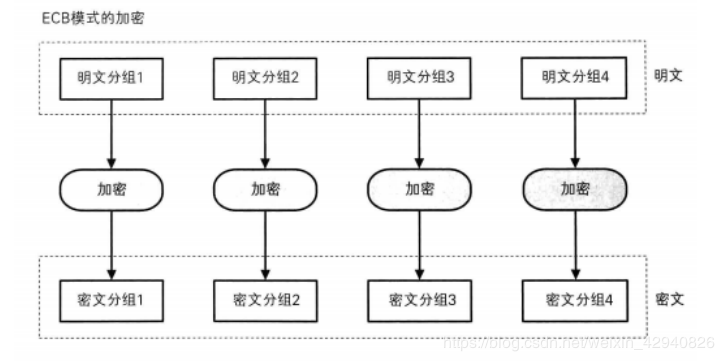
ECB模式(电子密码本模式)
加密前根据加密块大小(如AES为128位)分成若干块,之后将每块使用相同的密钥单独加密,解密同理。
ECB模式由于每块数据的加密是独立的因此加密和解密都可以并行计算,ECB模式最大的缺点是相同的明文块会被加密成相同的密文块,这种方法在某些环境下不能提供严格的数据保密性。
流程图如下:
实现代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
//电子密码本模式,分组大小为4
unsigned char* ECB(unsigned char *plain, int N)
{
int gNum = N / groupSize; //分组数量
//密文
unsigned char *cipher = new unsigned char[N];
int count = 0;
for (int i = 0; i < gNum; ++i)
{ unsigned char temp[groupSize];
for(int j = 0;j < groupSize;++j)
temp[j] = plain[count++];
//加密
encrypt(temp,groupSize);
for(int j = i*4;j < i*4 + 4;++j)
cipher[j] = temp[j - i * 4];
}
return cipher;//返回密文
}
|
解密方法也是让密文与密钥进行异或即可,实现效果如下:

CBC模式(分组链接模式)
CBC模式对于每个待加密的密码块在加密前会先与前一个密码块的密文异或然后再用加密器加密。第一个明文块与一个叫初始化向量的数据块异或。
可用公式总结为:
$$
C_i = E_K(P_i XOR C_{i-1}) \
C_{-1} = IV
$$
流程图如下:
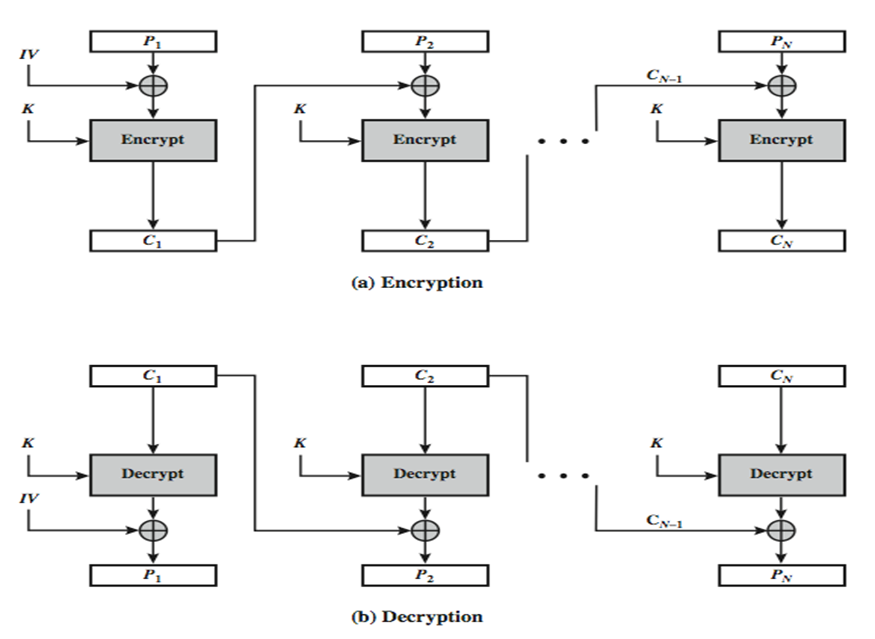
CBC模式相比ECB有更高的保密性,但由于对每个数据块的加密依赖与前一个数据块的加密所以加密无法并行。与ECB一样在加密前需要对数据进行填充,不是很适合对流数据进行加密。
代码如下:
加密函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
//CCB加密函数
unsigned char *CCB(unsigned char *plain, int N)
{
int gNum = N / groupSize; //分组数量
//密文
unsigned char *cipher = new unsigned char[N];
//设置初始向量
unsigned char C[groupSize] = {0xe4, 0xa9, 0x5d, 0x99};
int count = 0;
for (int i = 0; i < gNum; ++i)
{
unsigned char temp[groupSize];
for (int j = 0; j < groupSize; ++j)
temp[j] = plain[count++];
//加密
for (int j = 0; j < groupSize; ++j) //先与初始向量异或
temp[i] ^= C[i];
encrypt(temp, groupSize); //加密
for (int j = i * 4; j < i * 4 + 4; ++j)
{
cipher[j] = temp[j - i * 4];
C[j - i * 4] = temp[j - i * 4];//设置新向量
}
}
return cipher;
}
|
解密函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
//CCB解密函数
unsigned char *dCCB(unsigned char *cipher, int N)
{
int gNum = N / groupSize; //分组数量
//明文
unsigned char *plain = new unsigned char[N];
//设置初始向量
unsigned char C[groupSize] = {0xe4, 0xa9, 0x5d, 0x99};
int count = 0;
for (int i = 0; i < gNum; ++i)
{
unsigned char temp[groupSize];
for (int j = 0; j < groupSize; ++j)
temp[j] = cipher[count++];
//解密
encrypt(temp, groupSize); //先解密
for (int j = 0; j < groupSize; ++j) //然后与初始向量异或
temp[i] ^= C[i];
for (int j = i * 4; j < i * 4 + 4; ++j)
{
plain[j] = temp[j - i * 4];
C[j - i * 4] = cipher[j];//设置新向量
}
}
return plain;
}
|
实现效果:

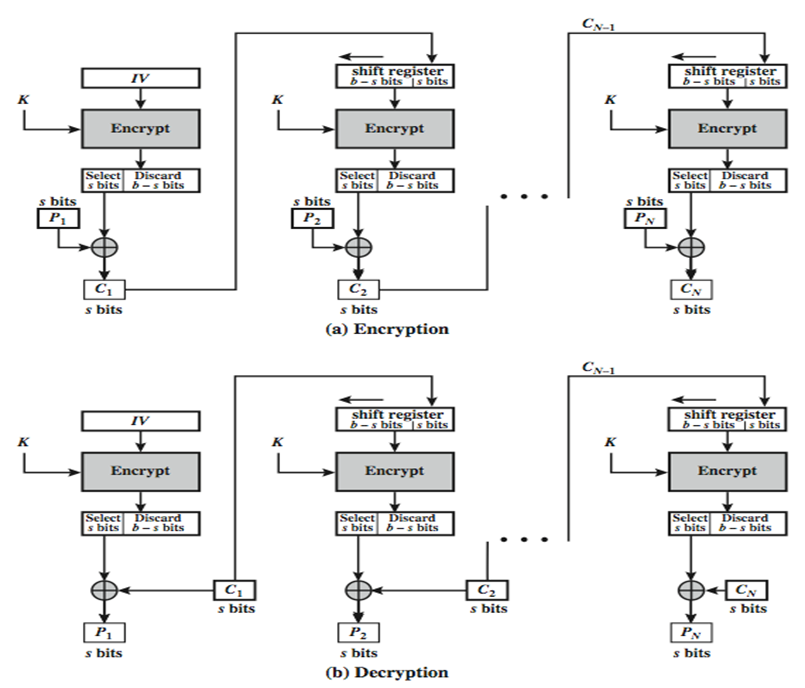
CFB模式(密文反馈模式)
与前面的模式不同,CFB模式可以将消息被当成是比特流.可以总结为如下的公式:
$$
C_i = P_i XOR E_K(C_{i-1})\
C_{-1} = IV
$$
流程图如下:
加密代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
//密文反馈模式,加密函数
unsigned char *CFB(unsigned char *plain, int N)
{
int gsize = 2;
int gNum = N / gsize; //分组数量,分成8组,每组大小为2
//密文
unsigned char *cipher = new unsigned char[N];
//设置初始向量
unsigned char C[4] = {0xe4, 0xa9, 0x5d, 0x99};
unsigned char S[2]; //前2个字节
int count = 0;
for (int i = 0; i < gNum; ++i)
{
unsigned char temp[gsize]; //分组明文,大小为2
for (int j = 0; j < gsize; ++j)
temp[j] = plain[count++];
//加密
//先对初始向量进行加密
encrypt(C,4);
//获取结果C的前两个bit,然后前2个bit S与明文进行异或
for(int j = 0;j < gsize;++j){
temp[j] ^= C[j];
S[j] = temp[j]; //获取密文的2bit
}
//设置密文
for (int j = i * gsize; j < i * gsize + gsize; ++j)
{
cipher[j] = temp[j - i * gsize];
}
//设置新向量,新向量左移
for(int j = 0;j < gsize;++j)
{
C[j] = C[j + gsize];
C[j + gsize] = S[j];
}
}
return cipher;
}
|
解密代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
//密文反馈解密
unsigned char *dCFB(unsigned char *cipher, int N)
{
int gsize = 2;
int gNum = N / gsize; //分组数量,分成8组,每组大小为2
//明文
unsigned char *plain = new unsigned char[N];
//设置初始向量
unsigned char C[4] = {0xe4, 0xa9, 0x5d, 0x99};
unsigned char S[2]; //前2个字节
int count = 0;
for (int i = 0; i < gNum; ++i)
{
unsigned char temp[gsize]; //分组密文
for (int j = 0; j < gsize; ++j)
temp[j] = cipher[count++];
//解密
//先对初始向量进行加密
encrypt(C,4);
//获取结果C的前两个bit,然后前2个bit S与明文进行异或
for(int j = 0;j < 2;++j){
S[j] = temp[j];
temp[j] = C[j] ^ temp[j];
}
//设置明文
for (int j = i * gsize; j < i * gsize + gsize; ++j)
{
plain[j] = temp[j - i * gsize];
}
//设置新向量,新向量左移
for(int j = 0;j < gsize;++j)
{
C[j] = C[j + gsize];
C[j+gsize] = S[j];
}
}
return plain;
}
|
实现效果:

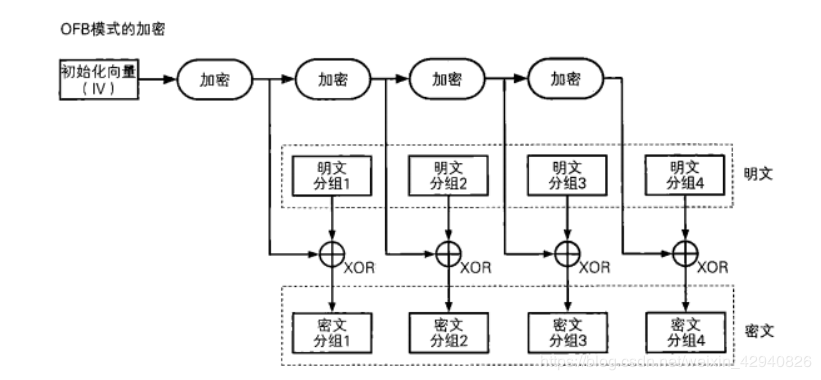
OFB模式(输出反馈模式)
OFB是先用块加密器生成密钥流(Keystream),然后再将密钥流与明文流异或得到密文流,解密是先用块加密器生成密钥流,再将密钥流与密文流异或得到明文,由于异或操作的对称性所以加密和解密的流程是完全一样的。
OFB与CFB一样都非常适合对流数据的加密,OFB由于加密和解密都依赖与前一段数据,所以加密和解密都不能并行。
流程图如下:
加密解密代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
//输出反馈模式,加密解密函数相同
unsigned char *OFB(unsigned char *plain, int N)
{
int gsize = 2;
int gNum = N / gsize; //分组数量,分成8组,每组大小为2
//密文
unsigned char *cipher = new unsigned char[N];
//设置初始向量
unsigned char C[4] = {0xee, 0xa9, 0x5d, 0x99};
unsigned char S[2]; //前2个字节
int count = 0;
for (int i = 0; i < gNum; ++i)
{
unsigned char temp[gsize]; //分组明文
for (int j = 0; j < gsize; ++j)
temp[j] = plain[count++];
//加密
//先对初始向量进行加密
encrypt(C,4);
//获取结果C的前两个bit,然后前2个bit S与明文进行异或
for(int j = 0;j < 2;++j){
S[j] = C[j]; //取向量加密后的前两位
temp[j] ^= C[j];
}
//设置密文
for (int j = i * gsize; j < i * gsize + gsize; ++j)
{
cipher[j] = temp[j - i * gsize];
}
//设置新向量,新向量左移
for(int j = 0;j < gsize;++j)
{
C[j] = C[j + gsize];
C[j + gsize] = S[j];
}
}
return cipher;
}
|
实现效果:

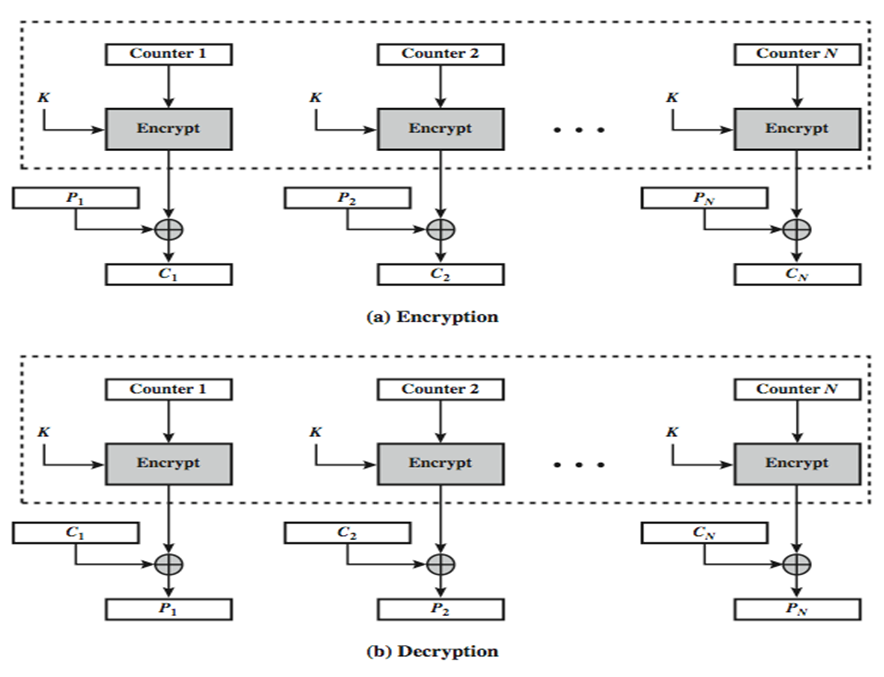
CTR模式(计数器模式)
类型于CFB,但是加密每个计数值,而不是任何反馈值,对每个明文分组,必须有不同的密钥和计数值 (从不重复使用),,可以用如下公式表示:
$$
O_i = E_K(i)\
C_i = P_i XOR O_i
$$
计数器模式流程图如下:
计数器模式加密函数与解密函数一样,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
//计数器模式,加密函数
unsigned char *CTR(unsigned char *plain, int N)
{
int gNum = N / groupSize; //分组数量
//密文
unsigned char *cipher = new unsigned char[N];
//设置随机值
unsigned char Counter[groupSize*groupSize] = {0x44, 0xa9, 0x5d, 0x99,
0xe5, 0xf1, 0x3d, 0x91,
0x16, 0xa6, 0xe1, 0x33,
0x22, 0xdd, 0xab, 0x1f};
int count = 0;
for (int i = 0; i < gNum; ++i)
{
unsigned char temp[groupSize]; //明文分组
unsigned char C[groupSize]; //分组随机值
for (int j = 0; j < groupSize; ++j)
{
temp[j] = plain[count++];
C[j] = Counter[i*4+j];
}
//加迷
//首先加密随机值C
encrypt(C, groupSize);
//然后与明文进行异或
for(int j = 0;j < groupSize;++j)
temp[j] ^= C[j];
//设置密文
for(int j = i*groupSize;j < i*groupSize+groupSize;j++)
cipher[j] = temp[j-i*groupSize];
}
return cipher;
}
|
实现效果如下:

参考: